
Aprende a realizar validación cruzada con 5 particiones en KNIME
La validación cruzada es una técnica muy utilizada en el campo del aprendizaje automático para evaluar el rendimiento de un modelo en datos no vistos. Esta técnica implica dividir los datos disponibles en conjuntos de entrenamiento y prueba, y repetir este proceso varias veces para obtener una estimación más robusta del rendimiento del modelo. KNIME es una plataforma de código abierto muy popular para el análisis de datos y la minería de datos, que también ofrece funcionalidades para realizar validación cruzada.
Te mostraré cómo puedes realizar la validación cruzada con 5 particiones en KNIME. Te guiaré a través de los pasos necesarios para configurar el flujo de trabajo en KNIME y te daré algunos consejos para interpretar los resultados obtenidos. También exploraremos las ventajas y las limitaciones de la validación cruzada y cómo puedes utilizar esta técnica para mejorar tus modelos de aprendizaje automático.
¿Qué verás en este artículo?
- Qué es la validación cruzada y por qué es importante en la minería de datos
- Cuál es la diferencia entre la validación cruzada con 5 particiones y otros métodos de validación
- Cuáles son los pasos necesarios para llevar a cabo una validación cruzada con 5 particiones en KNIME
- Cuál es la ventaja de utilizar KNIME para realizar la validación cruzada en lugar de otros softwares o lenguajes de programación
- Qué métricas se utilizan para evaluar el rendimiento de un modelo en la validación cruzada con 5 particiones
- Es posible ajustar el número de particiones en la validación cruzada en KNIME
- Cuál es la relación entre el tamaño del dataset y el número de particiones en la validación cruzada
-
Cuáles son las mejores prácticas para interpretar los resultados de la validación cruzada con 5 particiones en KNIME
- 1. Analizar la media y la desviación estándar de las métricas de rendimiento
- 2. Comparar las métricas de rendimiento entre particiones
- 3. Realizar pruebas estadísticas para determinar si las diferencias son significativas
- 4. Evaluar la consistencia de las clasificaciones
- 5. Considerar el contexto y los objetivos del problema
- Cómo se puede optimizar el proceso de validación cruzada en KNIME para obtener resultados más eficientes
- Es posible realizar una validación cruzada con 5 particiones en KNIME utilizando algoritmos de aprendizaje automático específicos
-
Preguntas frecuentes (FAQ)
- 1. ¿Qué es la validación cruzada?
- 2. ¿Por qué es importante utilizar la validación cruzada?
- 3. ¿Cuál es la diferencia entre la validación cruzada con k particiones y la validación cruzada con 5 particiones?
- 4. ¿Cómo se realiza la validación cruzada con 5 particiones en KNIME?
- 5. ¿Cuándo es recomendable utilizar la validación cruzada con 5 particiones?
Qué es la validación cruzada y por qué es importante en la minería de datos
La validación cruzada es una técnica utilizada en la minería de datos para evaluar la calidad de un modelo predictivo. Consiste en dividir el conjunto de datos en múltiples particiones, utilizando algunas de ellas para entrenar el modelo y el resto para probar su desempeño. A diferencia de la validación simple, que utiliza una única partición de prueba, la validación cruzada proporciona una evaluación más robusta del modelo al promediar los resultados de varias pruebas.
La validación cruzada es especialmente importante cuando se trabaja con conjuntos de datos pequeños, ya que permite aprovechar al máximo la información disponible. Además, al utilizar diferentes particiones para entrenar y probar el modelo, se reduce el riesgo de sobreajuste, lo que significa que el modelo será más generalizable a nuevos datos.
En la minería de datos, es fundamental evaluar la capacidad predictiva de los modelos antes de ponerlos en producción. La validación cruzada es una herramienta invaluable para lograr esto, ya que proporciona una medida objetiva del desempeño del modelo en diferentes conjuntos de datos. Esto permite identificar posibles problemas de generalización y ajustar el modelo en consecuencia.
Técnicas de validación cruzada comunes
- Validación cruzada de k-fold: Divide el conjunto de datos en k particiones y realiza k iteraciones, utilizando una partición diferente como conjunto de prueba en cada iteración y las restantes como conjunto de entrenamiento.
- Leave One Out (LOO): Para cada instancia del conjunto de datos, se entrena el modelo con todas las demás instancias y se evalúa su desempeño con la instancia excluida.
- Validación cruzada estratificada: Similar a la validación cruzada de k-fold, pero asegurando que las proporciones de clases en las particiones sean similares a las del conjunto de datos original.
Estas son solo algunas de las técnicas de validación cruzada más comunes, cada una con sus propias ventajas y desventajas. Es importante elegir la técnica adecuada para el problema y conjunto de datos específicos.
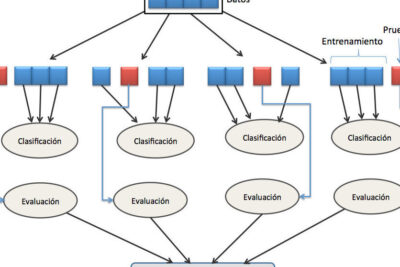
Validación cruzada con 5 particiones en KNIME
KNIME es una herramienta de minería de datos y análisis visual que ofrece una amplia gama de técnicas de validación cruzada, incluida la validación cruzada con k-fold. En el caso de utilizar 5 particiones, el conjunto de datos se divide en 5 partes iguales y se realizan 5 iteraciones, utilizando una partición diferente como conjunto de prueba en cada iteración.
La ventaja de utilizar 5 particiones en la validación cruzada es que se obtiene una estimación más precisa del rendimiento del modelo, ya que se utiliza una cantidad significativa de datos para entrenar y probar el modelo en cada iteración. Sin embargo, también implica un mayor tiempo de ejecución y requerimientos computacionales.
La validación cruzada es una técnica esencial en la minería de datos para evaluar la calidad de los modelos predictivos. KNIME ofrece diversas opciones para realizar validación cruzada, incluida la opción de utilizar 5 particiones. La elección de la técnica adecuada dependerá del problema y conjunto de datos específicos, así como de los recursos computacionales disponibles.
Cuál es la diferencia entre la validación cruzada con 5 particiones y otros métodos de validación
La validación cruzada es una técnica comúnmente utilizada para evaluar el rendimiento de un modelo predictivo. En lugar de dividir los datos en un conjunto de entrenamiento y un conjunto de prueba como lo haría la validación tradicional, la validación cruzada divide los datos en k subconjuntos llamados particiones.
La diferencia entre la validación cruzada con 5 particiones y otros métodos de validación radica en cómo se dividen los datos. Con la validación cruzada con 5 particiones, los datos se dividen en cinco conjuntos diferentes. El modelo se entrena en cuatro de estos conjuntos y se evalúa en el quinto conjunto. Este proceso se repite cinco veces, de modo que cada conjunto actúa como conjunto de prueba una vez y como conjunto de entrenamiento cuatro veces.
En contraste, otros métodos de validación, como la validación cruzada con 10 particiones o la validación cruzada con un solo conjunto de prueba, dividen los datos de manera ligeramente diferente. La elección del método de validación dependerá de la cantidad de datos disponibles, el tiempo de ejecución y los objetivos del modelo.
Cuáles son los pasos necesarios para llevar a cabo una validación cruzada con 5 particiones en KNIME
La validación cruzada es una técnica utilizada para evaluar el rendimiento de un modelo de aprendizaje automático. En KNIME, realizar una validación cruzada con 5 particiones implica seguir una serie de pasos:
Paso 1: Dividir el conjunto de datos en 5 partes iguales
El primer paso para realizar una validación cruzada con 5 particiones en KNIME es dividir el conjunto de datos en 5 partes iguales. Esto se puede hacer utilizando un nodo de división de datos en KNIME.
Paso 2: Configurar el nodo de validación cruzada
A continuación, se debe configurar un nodo de validación cruzada en KNIME. Este nodo permite especificar el número de particiones deseadas, en este caso 5. Además, se pueden establecer otras opciones, como el tipo de métrica de evaluación o la semilla aleatoria.
Paso 3: Configurar el modelo de aprendizaje automático
Una vez configurado el nodo de validación cruzada, es necesario establecer el modelo de aprendizaje automático que se va a utilizar. Esto puede incluir algoritmos como árboles de decisión, regresión logística o redes neuronales, entre otros.
Paso 4: Entrenar y evaluar el modelo en cada partición
Una vez configurado el modelo, se debe utilizar un nodo de entrenamiento y evaluación en KNIME para entrenar y evaluar el modelo en cada una de las particiones generadas. Esto implica entrenar el modelo con 4 particiones y evaluar su rendimiento en la partición restante, repitiendo este proceso 5 veces.
Paso 5: Calcular la media de las métricas de evaluación
Finalmente, para obtener una medida general del rendimiento del modelo, se deben calcular las métricas de evaluación en cada una de las particiones y obtener la media de estos valores. Esto proporcionará una estimación más robusta del rendimiento del modelo en el conjunto de datos.
Realizar una validación cruzada con 5 particiones en KNIME implica dividir el conjunto de datos en partes iguales, configurar el nodo de validación cruzada, establecer el modelo de aprendizaje automático, entrenar y evaluar el modelo en cada partición, y calcular la media de las métricas de evaluación.
Cuál es la ventaja de utilizar KNIME para realizar la validación cruzada en lugar de otros softwares o lenguajes de programación
KNIME es una herramienta de código abierto y ampliamente utilizada en el ámbito de la ciencia de datos y el aprendizaje automático. Una de las ventajas de utilizar KNIME para realizar la validación cruzada es su interfaz intuitiva y amigable para el usuario. No se requiere conocimiento previo en programación, lo que facilita su uso para aquellos que no son expertos en programación.
Otra ventaja de KNIME es su capacidad para manejar grandes volúmenes de datos. La validación cruzada implica dividir el conjunto de datos en k particiones y entrenar el modelo k veces. Con KNIME, este proceso se puede realizar de manera eficiente y rápida, incluso con grandes conjuntos de datos.
Además, KNIME ofrece una amplia gama de algoritmos y técnicas de modelado que se pueden utilizar en la validación cruzada. Esto permite a los usuarios elegir el mejor enfoque para su problema específico y obtener resultados más precisos.
Otro beneficio de utilizar KNIME para la validación cruzada es su capacidad para visualizar los resultados de una manera clara y concisa. KNIME proporciona herramientas para visualizar las métricas de evaluación del modelo, como la precisión, la precisión, el recall y la matriz de confusión. Esto facilita la interpretación de los resultados y la toma de decisiones basada en ellos.
KNIME es una excelente opción para realizar la validación cruzada debido a su interfaz intuitiva, capacidad para manejar grandes volúmenes de datos, variedad de algoritmos y técnicas de modelado, y capacidad de visualización de los resultados. Si buscas una herramienta poderosa y fácil de usar para realizar validación cruzada, KNIME es una excelente opción.
Qué métricas se utilizan para evaluar el rendimiento de un modelo en la validación cruzada con 5 particiones
En la validación cruzada con 5 particiones, se utilizan diversas métricas para evaluar el rendimiento de un modelo. Estas métricas permiten medir la capacidad de generalización del modelo y su capacidad para predecir valores precisos. Algunas de las métricas más comunes incluyen la precisión, el recall, el F1-score y el área bajo la curva (AUC). Estas métricas brindan información valiosa sobre la calidad del modelo y son esenciales para determinar si el modelo es adecuado para su implementación en el mundo real.
La precisión es una métrica que mide la proporción de predicciones correctas realizadas por el modelo. Se calcula dividiendo el número de predicciones correctas entre el número total de predicciones realizadas. El recall, por otro lado, es una métrica que mide la capacidad del modelo para identificar correctamente los casos positivos. Se calcula dividiendo el número de casos positivos correctamente identificados entre el número total de casos positivos.
El F1-score es una métrica que combina la precisión y el recall en un solo valor. Se calcula utilizando la siguiente fórmula: F1-score = 2 (precisión recall) / (precisión + recall). Esta métrica proporciona una medida equilibrada del rendimiento del modelo, teniendo en cuenta tanto la precisión como el recall.
Finalmente, el área bajo la curva (AUC) es una métrica utilizada en problemas de clasificación binaria. Representa la capacidad del modelo para distinguir entre las clases positiva y negativa. Un valor de AUC de 1 indica un modelo perfecto, mientras que un valor de 0.5 indica un modelo que no es mejor que el azar. Cuanto mayor sea el valor de AUC, mejor será el rendimiento del modelo.
Al evaluar el rendimiento de un modelo en la validación cruzada con 5 particiones, es importante considerar métricas como la precisión, el recall, el F1-score y el AUC. Estas métricas proporcionan información precisa sobre la calidad del modelo y son fundamentales para tomar decisiones informadas sobre su implementación.
Es posible ajustar el número de particiones en la validación cruzada en KNIME
La validación cruzada es una técnica comúnmente utilizada para evaluar el rendimiento de un modelo de aprendizaje automático. En KNIME, es posible ajustar el número de particiones utilizadas en este proceso.
La validación cruzada con 5 particiones implica dividir el conjunto de datos en 5 partes iguales. Luego, se entrena el modelo en 4 de estas partes y se evalúa en la restante. Este proceso se repite 5 veces, cada vez con una partición diferente como la de prueba.
El uso de 5 particiones en lugar de una sola partición ofrece una mejor estimación del rendimiento del modelo, ya que se utiliza una mayor cantidad de datos para evaluar su desempeño. Además, permite una validación más robusta y confiable.
En KNIME, configurar la validación cruzada con 5 particiones es muy sencillo. Simplemente se debe especificar este valor en el nodo de validación cruzada y el software se encargará de realizar las divisiones y el entrenamiento del modelo de manera automática.
Beneficios de la validación cruzada con 5 particiones
La validación cruzada con 5 particiones presenta varios beneficios para la evaluación y ajuste de modelos de aprendizaje automático. En primer lugar, al utilizar más datos para evaluar el modelo, se obtiene una estimación más precisa de su rendimiento en datos no vistos.
Además, al repetir el proceso 5 veces con particiones diferentes, se reducen los sesgos causados por una partición específica de los datos. Esto ayuda a obtener una evaluación más confiable y robusta del modelo, evitando resultados engañosos que puedan estar influenciados por un subconjunto particular de los datos.
Otro beneficio es que la validación cruzada con 5 particiones permite obtener información sobre la variabilidad del rendimiento del modelo. Al evaluar el modelo en diferentes particiones de los datos, se puede observar cómo varía su desempeño y determinar su estabilidad.
La validación cruzada con 5 particiones es una técnica poderosa para evaluar modelos de aprendizaje automático. En KNIME, su implementación es sencilla y ofrece beneficios significativos en términos de precisión, confiabilidad y estabilidad del modelo.
Cuál es la relación entre el tamaño del dataset y el número de particiones en la validación cruzada
La relación entre el tamaño del dataset y el número de particiones en la validación cruzada es un aspecto importante a considerar al diseñar un experimento. Cuando se tiene un dataset pequeño, es recomendable utilizar un número mayor de particiones para garantizar que todas las observaciones se utilicen tanto para entrenamiento como para validación. Por otro lado, en un dataset grande, se puede reducir el número de particiones sin que esto afecte significativamente la calidad de la validación cruzada.
La razón detrás de esto se encuentra en la proporción de datos de entrenamiento y validación. Para un dataset pequeño, si se utilizan pocas particiones, cada una contendrá una cantidad limitada de datos, lo que puede llevar a una menor representatividad de las muestras. Por el contrario, en un dataset grande, incluso con menos particiones, cada una contendrá una cantidad suficientemente grande de datos para representar adecuadamente las características generales del conjunto de datos.
La relación entre el tamaño del dataset y el número de particiones en la validación cruzada es inversamente proporcional. A medida que el tamaño del dataset aumenta, se puede utilizar un menor número de particiones sin comprometer la calidad de la validación cruzada.
Cuáles son las mejores prácticas para interpretar los resultados de la validación cruzada con 5 particiones en KNIME
La validación cruzada es una técnica de evaluación de modelos de aprendizaje automático que permite estimar la capacidad de generalización de un modelo. En KNIME, se puede realizar validación cruzada con diferentes particiones de los datos. En este artículo, nos centraremos en la validación cruzada con 5 particiones.
La validación cruzada con 5 particiones implica dividir el conjunto de datos en 5 partes iguales y usar 4 de ellas como conjunto de entrenamiento y la restante como conjunto de prueba. Este proceso se repite 5 veces, de manera que cada parte del conjunto de datos se utiliza una vez como conjunto de prueba.
Una vez que se ha realizado la validación cruzada con 5 particiones en KNIME, es importante interpretar correctamente los resultados obtenidos. Para ello, se pueden seguir algunas mejores prácticas:
1. Analizar la media y la desviación estándar de las métricas de rendimiento
El primer paso para interpretar los resultados de la validación cruzada con 5 particiones es analizar la media y la desviación estándar de las métricas de rendimiento, como la precisión o el área bajo la curva ROC. Estos valores proporcionan una medida promedio del rendimiento del modelo en cada partición.
2. Comparar las métricas de rendimiento entre particiones
Otra práctica importante es comparar las métricas de rendimiento entre las diferentes particiones de la validación cruzada. Esto permite identificar posibles variaciones en el rendimiento del modelo en diferentes subconjuntos de datos. Si las métricas de rendimiento varían ampliamente entre particiones, esto puede indicar una falta de estabilidad en el modelo.
3. Realizar pruebas estadísticas para determinar si las diferencias son significativas
Para determinar si las diferencias en las métricas de rendimiento entre particiones son estadísticamente significativas, se pueden realizar pruebas estadísticas adecuadas, como el test t de Student o el test de Wilcoxon. Estas pruebas permiten evaluar si las diferencias observadas son producto del azar o si realmente hay diferencias significativas entre las particiones.
4. Evaluar la consistencia de las clasificaciones
Además de analizar las métricas de rendimiento, es importante evaluar la consistencia de las clasificaciones realizadas por el modelo en las diferentes particiones. Esto se puede hacer mediante el cálculo de la matriz de confusión para cada partición y comparando las clasificaciones obtenidas.
5. Considerar el contexto y los objetivos del problema
Finalmente, al interpretar los resultados de la validación cruzada con 5 particiones, es crucial tener en cuenta el contexto y los objetivos específicos del problema. Las métricas de rendimiento pueden ser interpretadas de manera diferente dependiendo del dominio de aplicación y los requisitos del problema. Es importante considerar estos factores al tomar decisiones basadas en los resultados de la validación cruzada.
Cómo se puede optimizar el proceso de validación cruzada en KNIME para obtener resultados más eficientes
La validación cruzada es una técnica esencial en el aprendizaje automático para evaluar y validar modelos de predicción. En KNIME, esta herramienta puede optimizarse utilizando 5 particiones, lo que nos permitirá obtener resultados más eficientes.
La validación cruzada con 5 particiones implica dividir el conjunto de datos en 5 partes iguales y utilizar 4 partes para entrenar el modelo y la parte restante para evaluar su rendimiento. Este proceso se repite varias veces, asegurando que todas las partes del conjunto de datos se utilicen tanto para entrenar como para evaluar.
Al utilizar 5 particiones en lugar de una sola, obtenemos una mayor precisión en la evaluación del modelo. Esto se debe a que cada partición se utiliza tanto para entrenar como para evaluar, lo que reduce la posibilidad de errores y sesgos en la evaluación.
Para implementar la validación cruzada con 5 particiones en KNIME, podemos utilizar el nodo "Cross Validation Loop Start" seguido del nodo "Cross Validation Loop End". Estos nodos nos permiten especificar el número de particiones y realizar automáticamente el proceso de entrenamiento y evaluación del modelo en cada una de ellas.
Además, es importante mencionar que al utilizar 5 particiones en lugar de una sola, el proceso de validación cruzada puede llevar más tiempo debido al aumento en el número de iteraciones. Sin embargo, este tiempo adicional vale la pena, ya que obtenemos resultados más confiables y precisos.
La optimización del proceso de validación cruzada en KNIME utilizando 5 particiones nos permite obtener resultados más eficientes en la evaluación de modelos de predicción. Esta técnica reduce errores y sesgos, proporcionando una evaluación más precisa del rendimiento del modelo. Al implementar esta estrategia en KNIME, podemos aprovechar al máximo las capacidades de esta herramienta para mejorar nuestros análisis y tomar decisiones más informadas.
Es posible realizar una validación cruzada con 5 particiones en KNIME utilizando algoritmos de aprendizaje automático específicos
La validación cruzada es una técnica comúnmente utilizada en el aprendizaje automático para evaluar el rendimiento de un modelo. KNIME, una plataforma de ciencia de datos de código abierto, ofrece la posibilidad de realizar validación cruzada con 5 particiones utilizando algoritmos específicos.
La validación cruzada con 5 particiones implica dividir el conjunto de datos en 5 partes iguales o casi iguales. El modelo se entrena en 4 de las particiones y se evalúa en la restante. Este proceso se repite 5 veces, de manera que cada partición se utiliza una vez como conjunto de validación.
KNIME proporciona una amplia gama de algoritmos de aprendizaje automático que se pueden utilizar en combinación con la validación cruzada de 5 particiones. Estos algoritmos incluyen árboles de decisión, regresión logística, máquinas de vectores de soporte, entre otros. Cada algoritmo tiene sus propias características y requisitos, por lo que es importante seleccionar el más adecuado para el problema en cuestión.
Para realizar la validación cruzada con 5 particiones en KNIME, se requiere seguir algunos pasos. En primer lugar, se debe cargar el conjunto de datos en la plataforma y dividirlo en 5 partes iguales o casi iguales. A continuación, se selecciona el algoritmo de aprendizaje automático deseado y se configuran sus parámetros.
A continuación, se aplica el algoritmo a las 4 particiones de entrenamiento y se evalúa en la partición de validación. Este proceso se repite 5 veces, de manera que cada partición se utiliza una vez como conjunto de validación. Al finalizar, se obtienen métricas de evaluación del modelo, como precisión, recall y F1-score, que permiten determinar su rendimiento.
La validación cruzada con 5 particiones en KNIME es una técnica poderosa que ayuda a evaluar y comparar diferentes algoritmos de aprendizaje automático. Al realizar esta técnica, se evita la dependencia de un único conjunto de entrenamiento y se obtiene una evaluación más robusta del modelo.
Preguntas frecuentes (FAQ)
1. ¿Qué es la validación cruzada?
La validación cruzada es una técnica que permite evaluar de manera robusta el rendimiento de un modelo al dividir el conjunto de datos en diferentes particiones y evaluar el modelo en cada una de ellas.
2. ¿Por qué es importante utilizar la validación cruzada?
La validación cruzada es importante porque nos permite obtener una estimación más precisa del rendimiento del modelo al evaluarlo en diferentes particiones del conjunto de datos. Esto nos ayuda a evitar el sobreajuste y obtener un modelo más generalizable.
3. ¿Cuál es la diferencia entre la validación cruzada con k particiones y la validación cruzada con 5 particiones?
La diferencia radica en la cantidad de particiones en las que se divide el conjunto de datos. La validación cruzada con k particiones permite especificar el número de particiones que se desean utilizar, mientras que la validación cruzada con 5 particiones divide el conjunto de datos en 5 partes iguales.
4. ¿Cómo se realiza la validación cruzada con 5 particiones en KNIME?
En KNIME, se puede realizar la validación cruzada con 5 particiones utilizando el nodo "Partitioning" para dividir el conjunto de datos en 5 partes, y luego aplicando el nodo "Cross Validation Loop Start" y "Cross Validation Loop End" para iterar y evaluar el modelo en cada una de las particiones.
5. ¿Cuándo es recomendable utilizar la validación cruzada con 5 particiones?
La validación cruzada con 5 particiones es recomendable cuando se cuenta con un conjunto de datos de tamaño moderado y se quiere obtener una estimación más precisa del rendimiento del modelo. También puede ser útil cuando se desea comparar el rendimiento de diferentes modelos o ajustes de parámetros.
Envía mensajes en negrita a Slack con KNIME: paso a paso

Maximiza tus datos con SinPecadoPreprocesado en KNIME: Guía completa
KFold en KNIME: Valida datos con eficacia usando esta herramienta
Definir clase objetivo en KNIME: guía paso a paso
Domina los permisos en KNIME y sé un experto en sudo
Aprende cómo usar un nodo para sobredimensionar muestras en KNIME
Aprende a hacer validación cruzada con k-fold en KNIME
Descarta artículos y preposiciones en KNIME: consejos sencillos

Guía experta para leer y escribir archivos Parquet en KNIME
Deja una respuesta
Lo siento, debes estar conectado para publicar un comentario.
Artículos que podrían interesarte