

Búsqueda de relación entre variables en KNIME: paso a paso
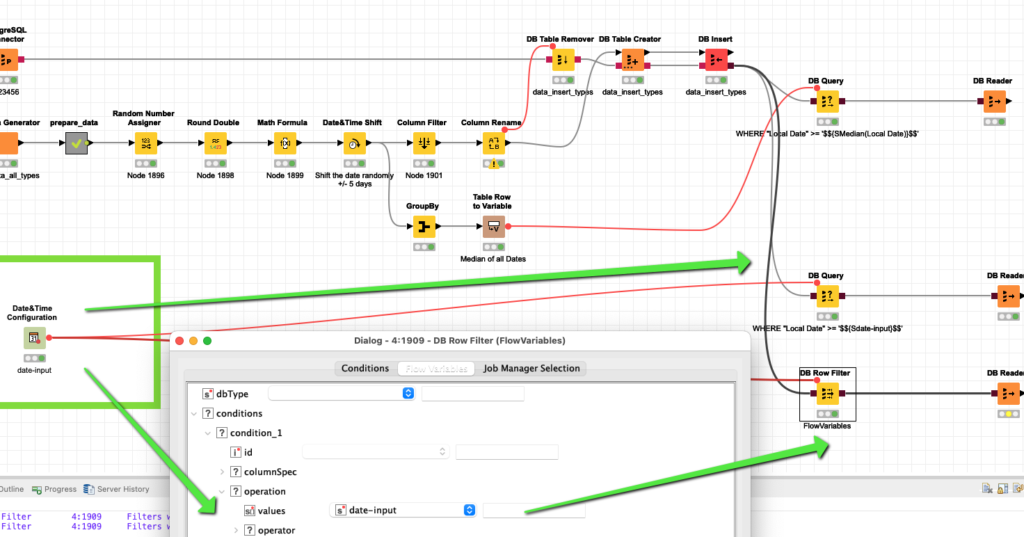
En el campo de la ciencia de datos y el análisis estadístico, una de las tareas más importantes es encontrar la relación entre diferentes variables. Esto nos permite comprender cómo cambia una variable en función de otra, identificar patrones y tendencias, y tomar decisiones informadas basadas en los datos. KNIME es una potente plataforma de análisis de datos que ofrece una variedad de herramientas y algoritmos para explorar y visualizar la relación entre variables de manera efectiva.
Te guiaré paso a paso a través del proceso de búsqueda de relación entre variables en KNIME. Aprenderás cómo importar y preparar tus datos, seleccionar las variables de interés, explorar las relaciones entre ellas utilizando diferentes métodos y herramientas de visualización, y finalmente interpretar los resultados para obtener conclusiones significativas. ¡Prepárate para sumergirte en el fascinante mundo de la búsqueda de relación entre variables en KNIME!
¿Qué verás en este artículo?
- Cuáles son las principales herramientas de análisis de datos en KNIME
- Cómo se pueden importar y preparar los datos en KNIME para el análisis
- Cuál es la importancia de explorar y visualizar los datos antes de realizar el análisis en KNIME
- Cuáles son las técnicas más comunes para analizar la relación entre variables en KNIME
- Es posible detectar correlaciones entre variables en KNIME? ¿Cómo se realiza este proceso
- Cómo se pueden identificar variables significativas en KNIME para un análisis más preciso
- Es posible realizar análisis de regresión en KNIME? ¿Cómo se puede utilizar esta técnica para buscar relaciones entre variables
- Cuáles son las ventajas de utilizar KNIME para buscar relaciones entre variables en comparación con otras herramientas de análisis de datos
- Existen casos o situaciones en los que KNIME no sea la mejor opción para buscar relaciones entre variables
- Cuál es la importancia de interpretar adecuadamente los resultados obtenidos al buscar relaciones entre variables en KNIME
- Preguntas frecuentes (FAQ)
Cuáles son las principales herramientas de análisis de datos en KNIME
KNIME es una plataforma de análisis de datos que ofrece una amplia gama de herramientas para realizar análisis avanzados. Algunas de las principales herramientas incluyen:
- Análisis estadístico: KNIME ofrece una variedad de nodos estadísticos para realizar cálculos y análisis estadísticos en los datos. Esto incluye herramientas como pruebas de hipótesis, regresión lineal y análisis de correlación.
- Minería de datos: KNIME cuenta con algoritmos de minería de datos preconfigurados que permiten descubrir patrones y relaciones ocultas en los datos. Esto incluye técnicas como árboles de decisión, clustering y reglas de asociación.
- Visualización de datos: KNIME proporciona herramientas para visualizar los datos de manera interactiva. Esto incluye gráficos, tablas y mapas que ayudan a comprender y comunicar los resultados del análisis.
- Procesamiento de texto: KNIME cuenta con nodos especializados en procesamiento de texto que permiten extraer información relevante de documentos de texto. Esto incluye técnicas como tokenización, lematización y análisis de sentimiento.
Estas son solo algunas de las muchas herramientas disponibles en KNIME para el análisis de datos. La plataforma es altamente flexible y se puede ampliar con nuevas herramientas y extensiones personalizadas según las necesidades del proyecto.
Cómo se pueden importar y preparar los datos en KNIME para el análisis
En KNIME, la importación y preparación de datos para el análisis es un paso fundamental. Para importar datos en KNIME, primero debemos seleccionar el nodo correspondiente en la barra de herramientas y arrastrarlo al lienzo de trabajo. Luego, debemos configurar el nodo para que apunte al archivo de datos que deseamos importar, ya sea un archivo CSV, Excel u otro formato compatible.
Una vez que hemos importado los datos en KNIME, podemos comenzar a prepararlos para el análisis. Esto implica realizar una serie de tareas, como la limpieza de datos, la eliminación de valores faltantes, la normalización de variables y la selección de características relevantes.
Para limpiar los datos en KNIME, podemos utilizar nodos como "Eliminar nodos" o "Eliminar filas duplicadas" para eliminar filas con valores faltantes o duplicados. También podemos utilizar el nodo "Reemplazar nodos" para reemplazar valores faltantes con valores medios o medianos.
La normalización de variables es otra tarea importante en la preparación de datos. La normalización nos permite escalar las variables a un rango común para garantizar que todas tengan un impacto similar en el análisis. En KNIME, podemos utilizar el nodo "Normalización" para realizar esta tarea, seleccionando la técnica de normalización adecuada según las características de los datos.
Por último, la selección de características relevantes también es esencial en la preparación de datos. Esta tarea implica identificar las características más importantes o significativas para el análisis y eliminar aquellas que no aportan valor. En KNIME, podemos utilizar técnicas como el análisis de componentes principales (PCA) o la eliminación recursiva de características para llevar a cabo esta tarea.
Cuál es la importancia de explorar y visualizar los datos antes de realizar el análisis en KNIME
Explorar y visualizar los datos antes de realizar el análisis en KNIME es crucial para comprender la estructura y la distribución de los datos. Esto nos ayuda a detectar posibles valores atípicos, entender las relaciones entre variables y evaluar la calidad de los datos.
Una forma efectiva de explorar los datos es utilizando gráficos, como el histograma para variables numéricas y el gráfico de barras para variables categóricas. Estos gráficos nos brindan una visión general de la distribución de los datos y nos permiten identificar posibles patrones o tendencias.
Además, la exploración de datos nos ayuda a identificar posibles problemas, como datos faltantes o inconsistentes, que deben ser abordados antes de realizar el análisis en KNIME. Es importante asegurarse de que los datos sean confiables y estén completos para obtener resultados precisos y confiables.
Explorar y visualizar los datos antes de analizarlos en KNIME nos ayuda a comprender mejor los datos, identificar patrones y tendencias, y garantizar la calidad de los mismos. Es un paso fundamental en el proceso de análisis de datos y nos proporciona una base sólida para tomar decisiones informadas.
Cuáles son las técnicas más comunes para analizar la relación entre variables en KNIME
La búsqueda de la relación entre variables es una parte fundamental del análisis de datos en KNIME. Existen diversas técnicas que nos permiten explorar estas relaciones y obtener información valiosa. Algunas de las más comunes incluyen el análisis de correlación, la regresión lineal, el análisis de componentes principales y el clustering.
El análisis de correlación nos ayuda a determinar si existe una relación lineal entre dos variables. Esto se puede visualizar mediante un gráfico de dispersión y se cuantifica mediante el coeficiente de correlación. Por otro lado, la regresión lineal nos permite modelar la relación entre una variable dependiente y una o más variables independientes.
El análisis de componentes principales es una técnica utilizada para reducir la dimensionalidad de un conjunto de datos. Nos permite identificar las variables más importantes que explican la mayor parte de la variabilidad en los datos. Esto es útil cuando tenemos un gran número de variables y queremos simplificar el análisis.
Por último, el clustering es una técnica que nos permite agrupar variables similares en grupos. Esto es útil cuando queremos identificar patrones o segmentar nuestros datos en diferentes categorías. Existen diferentes algoritmos de clustering disponibles en KNIME, como el k-means y el clustering jerárquico.
Es posible detectar correlaciones entre variables en KNIME? ¿Cómo se realiza este proceso
En KNIME, es posible detectar correlaciones entre variables mediante varias técnicas y herramientas disponibles en la plataforma. Uno de los métodos más comunes es el cálculo del coeficiente de correlación de Pearson, que permite cuantificar la relación lineal entre dos variables numéricas. Este proceso se puede realizar mediante el uso del nodo "Correlation Calculator" en KNIME, el cual proporciona una matriz de correlación para todas las variables seleccionadas. Además, KNIME también ofrece otras técnicas de correlación, como el coeficiente de correlación de Spearman o el coeficiente de Kendall.
Paso 1: Preparación de datos
Antes de comenzar a buscar correlaciones entre variables en KNIME, es importante realizar una adecuada preparación de los datos. Esto implica asegurarse de que los datos estén limpios, sin valores faltantes o atípicos, y que las variables sean del tipo adecuado (numéricas, categóricas, etc.). KNIME ofrece una amplia gama de nodos para la preparación de datos, como el nodo "Missing Value" para tratar valores faltantes, o el nodo "Outlier Detection" para identificar valores atípicos. Estos nodos se pueden utilizar como parte de un flujo de trabajo antes de realizar el cálculo de correlaciones.
Paso 2: Configuración del nodo "Correlation Calculator"
Una vez que los datos estén preparados, se puede proceder a configurar el nodo "Correlation Calculator" en KNIME. Este nodo requiere que se seleccionen las variables entre las cuales se desea encontrar correlaciones. Además, se pueden especificar otras opciones de configuración, como el tipo de coeficiente de correlación a utilizar (Pearson, Spearman o Kendall), y si se desea calcular la matriz de correlación completa o solo las correlaciones parciales. Una vez configurado el nodo, se puede ejecutar el flujo de trabajo para obtener los resultados.
Paso 3: Interpretación de los resultados
Una vez que se haya realizado el cálculo de correlaciones en KNIME, es importante interpretar los resultados obtenidos. La matriz de correlación proporciona una medida de la relación entre cada par de variables seleccionadas. Los valores de la matriz varían entre -1 y 1, donde un valor cercano a -1 indica una correlación negativa fuerte, un valor cercano a 1 indica una correlación positiva fuerte, y un valor cercano a 0 indica una falta de correlación. Además, es posible visualizar los resultados utilizando gráficos como scatter plots o heatmaps, lo que puede facilitar la comprensión de las relaciones entre variables.
Consideraciones y conclusiones
Es importante tener en cuenta que el cálculo de correlaciones en KNIME no implica necesariamente una relación causal entre las variables. Las correlaciones pueden ser útiles para identificar patrones o tendencias en los datos, pero no proporcionan evidencia de una relación de causa y efecto. Por lo tanto, es necesario realizar un análisis más profundo y considerar otros factores antes de sacar conclusiones definitivas. KNIME ofrece herramientas y técnicas poderosas para buscar correlaciones entre variables, pero es fundamental realizar una correcta preparación de los datos y una interpretación adecuada de los resultados para obtener conclusiones significativas.
Cómo se pueden identificar variables significativas en KNIME para un análisis más preciso
En KNIME, es posible buscar la relación entre variables para poder realizar un análisis más preciso de los datos. Identificar las variables significativas es esencial para obtener resultados confiables y relevantes. A continuación, te mostraré un paso a paso para realizar este proceso en KNIME.
Paso 1: Preparación de los datos
El primer paso consiste en preparar los datos para el análisis. Esto implica preprocesar los datos, eliminar cualquier valor atípico o inconsistencia, y asegurarse de que los datos estén en el formato adecuado. KNIME ofrece diversas herramientas y nodos para realizar esta tarea de manera sencilla y eficiente.
Paso 2: Selección de variables
Una vez que los datos están preparados, es importante seleccionar las variables que se utilizarán en el análisis. KNIME proporciona diferentes métodos de selección de variables, como el análisis de correlación, la prueba de chi-cuadrado, el análisis de importancia o el análisis de componentes principales. Estos métodos permiten identificar las variables que tienen una mayor influencia en los resultados del análisis.
Paso 3: Análisis de correlación
Una vez que se han seleccionado las variables, se puede realizar un análisis de correlación para identificar las relaciones entre ellas. KNIME ofrece diversas herramientas y nodos para calcular la correlación entre variables, como el coeficiente de correlación de Pearson o el coeficiente de correlación de Spearman. Este análisis permite identificar las variables que tienen una mayor relación entre sí y que pueden ser relevantes para el análisis.
Paso 4: Prueba de significancia
Una vez identificadas las variables que tienen una mayor relación, es importante realizar una prueba de significancia para determinar si esta relación es estadísticamente significativa. KNIME ofrece diversas pruebas estadísticas, como la prueba t de Student o el análisis de varianza (ANOVA), que permiten determinar si las diferencias observadas entre las variables son significativas o simplemente resultado del azar.
Paso 5: Interpretación de los resultados
Una vez finalizado el análisis, es importante interpretar los resultados obtenidos. KNIME proporciona diferentes herramientas y nodos para visualizar los resultados de manera clara y comprensible. Esto incluye gráficos de dispersión, gráficos de barras o diagramas de caja y bigotes, que permiten identificar patrones o tendencias en los datos y facilitan la interpretación de los resultados.
La búsqueda de relación entre variables en KNIME es un proceso fundamental para realizar un análisis más preciso de los datos. Siguiendo estos pasos, podrás identificar las variables significativas y obtener resultados confiables y relevantes.
Es posible realizar análisis de regresión en KNIME? ¿Cómo se puede utilizar esta técnica para buscar relaciones entre variables
¡Claro que es posible realizar análisis de regresión en KNIME! Esta plataforma de código abierto ofrece una amplia variedad de herramientas y nodos que permiten realizar análisis estadísticos de forma sencilla y eficiente.
El análisis de regresión es una técnica que nos permite investigar la relación entre una variable dependiente y una o más variables independientes. KNIME nos brinda la posibilidad de aplicar diferentes tipos de regresión, como la regresión lineal, regresión logística, regresión polinomial, entre otras.
Para utilizar la técnica de regresión en KNIME, primero debemos preparar nuestros datos. Podemos importar nuestros conjuntos de datos en diferentes formatos, como CSV, Excel, SQL, entre otros. Una vez que nuestros datos están cargados en KNIME, podemos iniciar el análisis.
El siguiente paso es configurar los nodos necesarios para realizar el análisis de regresión en KNIME. Los nodos representan diferentes etapas del proceso, como limpieza de datos, transformación, selección de variables y modelado. Podemos arrastrar y soltar estos nodos en el flujo de trabajo y configurar sus parámetros según nuestras necesidades.
Una vez que hemos configurado los nodos necesarios, podemos ejecutar el flujo de trabajo y obtener los resultados. KNIME nos proporciona diferentes tipos de resultados, como coeficientes de regresión, estadísticas de ajuste del modelo, gráficos de residuos, entre otros. Estos resultados nos ayudarán a interpretar y evaluar la relación entre las variables.
KNIME nos ofrece una plataforma versátil y fácil de usar para realizar análisis de regresión y buscar relaciones entre variables. Con sus numerosas herramientas y nodos, podemos explorar diferentes técnicas y obtener información valiosa para la toma de decisiones.
Cuáles son las ventajas de utilizar KNIME para buscar relaciones entre variables en comparación con otras herramientas de análisis de datos
KNIME es una poderosa herramienta de análisis de datos que ofrece numerosas ventajas cuando se trata de buscar relaciones entre variables. A diferencia de otras herramientas, KNIME es altamente flexible y permite a los usuarios personalizar su proceso de análisis según sus necesidades específicas. Además, KNIME proporciona un entorno visual intuitivo que facilita la creación de flujos de trabajo complejos sin necesidad de escribir código. Esto hace que la búsqueda de relaciones entre variables sea más accesible para aquellos que no tienen conocimientos avanzados en programación.
Otra ventaja de KNIME es su capacidad para procesar grandes volúmenes de datos de manera eficiente. KNIME utiliza un enfoque basado en nodos que permite a los usuarios realizar operaciones de análisis en paralelo, lo que acelera significativamente el tiempo de ejecución. Esto es especialmente útil cuando se trabaja con conjuntos de datos grandes y complejos.
Además, KNIME ofrece una amplia gama de algoritmos y técnicas de análisis de datos que permiten a los usuarios explorar y descubrir relaciones entre variables de manera efectiva. Estos algoritmos incluyen desde técnicas básicas como la correlación y la regresión hasta técnicas más avanzadas como el aprendizaje automático y la minería de texto. Esto brinda a los usuarios una mayor flexibilidad y posibilidad de descubrir relaciones más complejas y significativas en sus datos.
Utilizar KNIME para buscar relaciones entre variables ofrece ventajas significativas en términos de flexibilidad, velocidad de procesamiento y variedad de algoritmos disponibles. Esto hace que KNIME sea una opción recomendada para aquellos que buscan una herramienta poderosa y fácil de usar para el análisis de datos.
Existen casos o situaciones en los que KNIME no sea la mejor opción para buscar relaciones entre variables
Si bien KNIME es una herramienta poderosa para buscar relaciones entre variables, hay situaciones en las que puede no ser la opción más adecuada. Por ejemplo, si el conjunto de datos es extremadamente grande y complejo, KNIME podría tener dificultades para manejarlos eficientemente. En este caso, herramientas más especializadas en el análisis de big data podrían resultar más efectivas.
También es importante tener en cuenta que KNIME es una herramienta basada en nodos que requiere cierto conocimiento técnico para su configuración y uso. Si no se cuenta con la experiencia necesaria para aprovechar al máximo todas las funcionalidades de KNIME, podría resultar más conveniente utilizar una herramienta más intuitiva y fácil de usar.
Además, KNIME puede tener limitaciones en términos de algoritmos y métodos de análisis disponibles. Si se requiere utilizar un algoritmo o técnica de análisis específica que no está incluido en KNIME, puede resultar necesario recurrir a otras herramientas o lenguajes de programación.
Si bien KNIME es una buena opción en muchos casos, es importante evaluar las características y necesidades específicas del proyecto antes de decidir si es la herramienta más adecuada para buscar relaciones entre variables.
Cuál es la importancia de interpretar adecuadamente los resultados obtenidos al buscar relaciones entre variables en KNIME
La interpretación adecuada de los resultados obtenidos al buscar relaciones entre variables en KNIME es crucial para comprender la relación subyacente entre los datos y tomar decisiones informadas. Al comprender las relaciones, se pueden identificar patrones, tendencias y posibles causas y efectos, lo que ayuda en la toma de decisiones y la resolución de problemas. Además, una interpretación adecuada también puede ayudar a detectar errores o sesgos en los datos y garantizar la confiabilidad y validez de los resultados. Por lo tanto, es fundamental dedicar tiempo y esfuerzo a la interpretación de los resultados de la búsqueda de relaciones entre variables en KNIME.
Preguntas frecuentes (FAQ)
1. ¿Qué es KNIME?
KNIME es una plataforma de código abierto que permite el análisis de datos y la creación de flujos de trabajo.
2. ¿Cómo puedo instalar KNIME en mi ordenador?
Puedes descargar e instalar KNIME desde su página oficial, donde encontrarás las versiones para diferentes sistemas operativos.
3. ¿Qué tipos de datos puedo analizar con KNIME?
KNIME admite una amplia variedad de tipos de datos, incluyendo datos estructurados, no estructurados y semi estructurados.
4. ¿Cuáles son los pasos básicos para realizar un análisis de datos en KNIME?
Los pasos básicos para realizar un análisis de datos en KNIME incluyen la importación de datos, la manipulación y transformación de los datos, y la visualización de los resultados.
5. ¿Puedo compartir mis flujos de trabajo en KNIME?
Sí, KNIME permite compartir flujos de trabajo con otros usuarios, lo que facilita la colaboración y el intercambio de conocimientos.
Maximiza tus datos con SinPecadoPreprocesado en KNIME: Guía completa
KFold en KNIME: Valida datos con eficacia usando esta herramienta
Definir clase objetivo en KNIME: guía paso a paso
Domina los permisos en KNIME y sé un experto en sudo
Aprende cómo usar un nodo para sobredimensionar muestras en KNIME
Aprende a hacer validación cruzada con k-fold en KNIME
Descarta artículos y preposiciones en KNIME: consejos sencillos

Guía experta para leer y escribir archivos Parquet en KNIME
KNIME: Crea un bucle simple para leer varios archivos
Deja una respuesta
Lo siento, debes estar conectado para publicar un comentario.
Artículos que podrían interesarte