
Detecta anomalías en machine learning con KNIME: consejos expertos
Con el crecimiento exponencial de los datos en la última década, el machine learning se ha vuelto fundamental en muchas industrias para extraer información valiosa y tomar decisiones inteligentes. Sin embargo, a medida que los algoritmos de aprendizaje automático se vuelven más complejos, también aumenta la posibilidad de que se produzcan anomalías o errores en los resultados. Detectar estas anomalías se ha convertido en un desafío crítico para garantizar la confiabilidad de los modelos de machine learning.
Exploraremos cómo KNIME, una plataforma de código abierto para el análisis de datos y la creación de modelos, puede ayudarnos a detectar y manejar las anomalías en nuestros proyectos de machine learning. Analizaremos consejos y técnicas expertas para identificar y abordar posibles errores en los datos y en los modelos, así como la importancia de la interpretación y la transparencia en el proceso de detección de anomalías.
¿Qué verás en este artículo?
- Cuáles son las principales herramientas de detección de anomalías en machine learning que ofrece KNIME
- Cómo puedo utilizar KNIME para identificar patrones no deseados en los datos
- Qué pasos debo seguir para preparar mis datos antes de utilizar KNIME para detectar anomalías
- Es posible detectar anomalías en tiempo real utilizando KNIME? ¿Cómo se logra esto
- Cuáles son las ventajas de utilizar KNIME en comparación con otras herramientas de detección de anomalías en machine learning
- Cuáles son los principales desafíos que enfrentan los usuarios al utilizar KNIME para detectar anomalías y cómo se pueden superar
- Existe alguna forma de automatizar el proceso de detección de anomalías en KNIME
- Cuáles son los diferentes algoritmos de detección de anomalías disponibles en KNIME y en qué situaciones se recomienda su uso
- Qué pasos puedo seguir para evaluar la efectividad de los resultados obtenidos al utilizar KNIME para detectar anomalías
- Cómo puedo visualizar y comunicar los resultados de las detecciones de anomalías realizadas con KNIME de manera efectiva
- Cuáles son los ejemplos de casos de uso más comunes en los que se utiliza KNIME para detectar anomalías en machine learning
- Existen recursos adicionales, como tutoriales o documentación, que puedan ayudarme a aprender a utilizar KNIME para detectar anomalías
-
Preguntas frecuentes (FAQ)
- 1. ¿Qué es KNIME y cómo puedo usarlo para detectar anomalías en datos?
- 2. ¿Cuál es la importancia de detectar anomalías en machine learning?
- 3. ¿Cuáles son algunas técnicas comunes para detectar anomalías en datos utilizando KNIME?
- 4. ¿Cómo puedo evaluar la efectividad de la detección de anomalías en KNIME?
- 5. ¿Qué precauciones debo tomar al utilizar KNIME para detectar anomalías en datos?
Cuáles son las principales herramientas de detección de anomalías en machine learning que ofrece KNIME
KNIME es una potente herramienta de código abierto que ofrece diversas opciones para detectar anomalías en el aprendizaje automático. Una de las principales herramientas que ofrece KNIME es el algoritmo One-Class Support Vector Machine (SVM). Este algoritmo se utiliza para detectar observaciones anómalas en un conjunto de datos utilizando un enfoque de aprendizaje no supervisado.
Otra herramienta que KNIME ofrece es el algoritmo Local Outlier Factor (LOF). Este algoritmo se utiliza para detectar anomalías en un conjunto de datos basado en la densidad local de las observaciones. Identifica aquellas observaciones que se encuentran en regiones menos densas del conjunto de datos.
Además, KNIME cuenta con el algoritmo Isolation Forest, el cual se basa en el concepto de árboles de decisión aleatorios para detectar anomalías. Este algoritmo aísla las anomalías en las ramas más cortas de los árboles, lo que permite una detección más precisa.
Consejos expertos para detectar anomalías con KNIME
Para aprovechar al máximo las herramientas de detección de anomalías de KNIME, es importante seguir algunos consejos:
- Asegúrate de comprender bien los algoritmos de detección de anomalías que ofrece KNIME. Esto te permitirá elegir el mejor algoritmo para tu conjunto de datos y entender los resultados que obtengas.
- Realiza un análisis exploratorio de tus datos antes de aplicar los algoritmos de detección de anomalías. Esto te ayudará a identificar posibles patrones o características que puedan indicar la presencia de anomalías.
- Considera la posibilidad de utilizar técnicas de preprocesamiento de datos, como la normalización o la eliminación de outliers, antes de aplicar los algoritmos de detección de anomalías. Esto puede mejorar la precisión de los resultados.
- Evalúa y compara los resultados obtenidos utilizando diferentes algoritmos de detección de anomalías. Esto te permitirá identificar cuál es el más adecuado para tu conjunto de datos y ajustar los parámetros en consecuencia.
KNIME ofrece diversas herramientas y consejos expertos para detectar anomalías en el aprendizaje automático. Aprovechar al máximo estas herramientas puede ayudarte a mejorar la precisión de tus modelos y detectar posibles problemas en tus datos.
Cómo puedo utilizar KNIME para identificar patrones no deseados en los datos
KNIME es una poderosa herramienta de machine learning que también puede utilizarse para detectar anomalías en los datos. Al utilizar KNIME, puedes aplicar diferentes técnicas y algoritmos para identificar patrones no deseados en tus datos y tomar medidas preventivas.
Una de las formas más comunes de detectar anomalías en KNIME es mediante el uso de algoritmos de detección de outliers. Estos algoritmos analizan los datos y buscan valores que se desvíen significativamente de la norma. KNIME ofrece una variedad de algoritmos de detección de outliers, como el algoritmo de distancia euclidiana o el algoritmo de desviación estándar.
Otra forma de detectar anomalías en KNIME es mediante el uso de algoritmos de clustering. Estos algoritmos agrupan los datos en grupos o clústeres, y cualquier dato que no encaje bien en ningún clúster puede considerarse una anomalía. KNIME ofrece algoritmos populares de clustering, como el algoritmo K-means o el algoritmo de agrupamiento jerárquico.
Además de los algoritmos específicos, KNIME también ofrece una amplia gama de herramientas de preprocesamiento de datos que pueden ayudarte a identificar anomalías. Puedes utilizar transformaciones de datos para normalizar tus datos y reducir cualquier ruido o variación no deseada. También puedes utilizar filtrado de datos para eliminar cualquier valor atípico o ruido en tus datos.
Una vez que hayas identificado las anomalías en tus datos, KNIME te permite tomar medidas preventivas para evitar posibles impactos negativos. Puedes utilizar técnicas de imputación de datos para reemplazar los valores anómalos con valores estimados o puedes eliminar completamente los datos anómalos si no son relevantes para tu análisis.
KNIME es una herramienta poderosa que te permite detectar anomalías en tus datos utilizando diferentes técnicas y algoritmos. Ya sea a través de la detección de outliers, clustering o preprocesamiento de datos, KNIME te brinda las herramientas necesarias para identificar y tomar medidas preventivas contra patrones no deseados en tus datos de machine learning.
Qué pasos debo seguir para preparar mis datos antes de utilizar KNIME para detectar anomalías
Antes de utilizar KNIME para detectar anomalías en machine learning, es fundamental preparar los datos de manera adecuada. Aquí te presentamos algunos pasos que debes seguir:
1. Exploración de los datos
Realiza un análisis exploratorio de los datos para comprender su estructura y características. Examina la distribución de los valores, identifica posibles valores atípicos y verifica la presencia de datos faltantes.
2. Limpieza de los datos
Elimina los valores atípicos y los datos faltantes de manera adecuada. Puedes optar por eliminar las filas o imputar los valores faltantes utilizando técnicas como la media, la mediana o la moda.
3. Normalización de los datos
En muchos casos, la normalización de los datos es necesaria para asegurar que todas las características tengan el mismo rango. Puedes utilizar técnicas como la estandarización o la escala min-max.
4. Selección de características
Si tus datos contienen muchas características, considera realizar una selección de características para reducir la dimensionalidad y mejorar el rendimiento de los algoritmos de detección de anomalías. Utiliza técnicas como la correlación o algoritmos de selección de características.
5. División de los datos
Divide tus datos en conjuntos de entrenamiento y prueba. El conjunto de entrenamiento se utilizará para entrenar el modelo de detección de anomalías, mientras que el conjunto de prueba se utilizará para evaluar el rendimiento del modelo.
6. Aplicación de KNIME
Finalmente, utiliza KNIME para aplicar algoritmos de detección de anomalías a tus datos preparados. KNIME cuenta con una amplia gama de nodos y herramientas que te ayudarán a detectar anomalías de manera eficiente y precisa.
Al seguir estos pasos, estarás preparado para utilizar KNIME de manera efectiva y obtener resultados confiables en la detección de anomalías en machine learning.
Es posible detectar anomalías en tiempo real utilizando KNIME? ¿Cómo se logra esto
Sí, es posible detectar anomalías en tiempo real utilizando KNIME. Esto se logra mediante el uso de algoritmos de machine learning que analizan los datos en busca de patrones anómalos. KNIME ofrece una amplia gama de herramientas y funciones para facilitar este proceso.
Uno de los enfoques más comunes es utilizar algoritmos de detección de anomalías como el algoritmo One-class Support Vector Machines (SVM), que es capaz de identificar puntos de datos que se desvían significativamente de la norma. KNIME también ofrece otros algoritmos, como el Local Outlier Factor (LOF) y el Isolation Forest, que son eficaces para detectar anomalías en diferentes escenarios.
Para utilizar KNIME en la detección de anomalías en tiempo real, es necesario configurar un flujo de trabajo que incluya la conexión en tiempo real con los datos de entrada. Esto se puede lograr mediante la configuración de nodos de entrada y salida en el flujo de trabajo de KNIME.
Consejos para la detección de anomalías en tiempo real con KNIME
- Configura la conexión en tiempo real con los datos de entrada para asegurar un monitoreo continuo y actualizado de los datos.
- Utiliza algoritmos de detección de anomalías apropiados para el tipo de datos que estás analizando.
- Considera la inclusión de técnicas de preprocesamiento de datos para mejorar la calidad de los resultados de detección de anomalías.
- Realiza pruebas exhaustivas y ajustes finos de los algoritmos utilizados para maximizar la precisión y minimizar los falsos positivos.
- Utiliza visualizaciones interactivas para explorar y comprender mejor las anomalías detectadas, lo que puede ayudar en la toma de decisiones.
La detección de anomalías en tiempo real utilizando KNIME es posible y ofrece una solución robusta y flexible para identificar patrones anómalos en los datos. Siguiendo algunos consejos expertos, puedes configurar un flujo de trabajo eficiente y obtener resultados precisos y confiables en la detección de anomalías.
Cuáles son las ventajas de utilizar KNIME en comparación con otras herramientas de detección de anomalías en machine learning
KNIME es una poderosa herramienta de código abierto que ofrece numerosas ventajas en comparación con otras herramientas de detección de anomalías en machine learning.
En primer lugar, KNIME es altamente flexible y permite a los usuarios personalizar su flujo de trabajo según sus necesidades específicas. Esto significa que puedes adaptar KNIME a tus propios algoritmos y técnicas de detección de anomalías.
Además, KNIME ofrece una amplia gama de nodos y extensiones predefinidas que facilitan la detección de anomalías en diferentes tipos de datos, incluyendo datos estructurados y no estructurados. Estos nodos predefinidos pueden ahorrar tiempo y esfuerzo a los analistas de datos.
Otra ventaja de KNIME es su capacidad de integración con otras herramientas y lenguajes de programación, como Python y R. Esto permite a los usuarios aprovechar las bibliotecas y algoritmos más avanzados disponibles en estas plataformas.
Finalmente, KNIME ofrece una interfaz gráfica de usuario intuitiva y fácil de usar, lo que facilita el proceso de detección de anomalías incluso para aquellos que no son expertos en programación o machine learning.
Utilizar KNIME para la detección de anomalías en machine learning ofrece ventajas significativas en términos de flexibilidad, funcionalidad, integración y usabilidad. Es una herramienta que vale la pena considerar para aquellos que buscan optimizar su proceso de detección de anomalías.
Cuáles son los principales desafíos que enfrentan los usuarios al utilizar KNIME para detectar anomalías y cómo se pueden superar
Al utilizar KNIME para detectar anomalías en machine learning, los usuarios suelen enfrentar varios desafíos. Uno de los principales es la falta de conocimiento sobre cómo configurar adecuadamente los algoritmos de detección de anomalías. Esto puede llevar a resultados inexactos o sesgados.
Otro desafío común es el manejo de grandes volúmenes de datos. KNIME, al ser una herramienta visual y escalable, permite realizar análisis de anomalías en conjuntos de datos masivos. Sin embargo, el procesamiento y la interpretación de estos datos puede ser complicado y requiere conocimientos técnicos sólidos.
Además, la interpretación de los resultados también puede ser un desafío. KNIME proporciona visualizaciones y métricas para evaluar las anomalías detectadas, pero la interpretación adecuada de estas métricas requiere una comprensión profunda del dominio y del contexto del problema.
Para superar estos desafíos, es importante contar con un buen conocimiento de los algoritmos de detección de anomalías disponibles en KNIME y cómo configurarlos de manera adecuada. Además, es necesario tener habilidades en el manejo de datos y visualización para analizar y comprender los resultados obtenidos.
Consejos expertos para enfrentar los desafíos en la detección de anomalías con KNIME
- Investigar y familiarizarse con los diferentes algoritmos de detección de anomalías que ofrece KNIME. Comprender cómo funcionan y cuándo es adecuado utilizar cada uno en función del tipo de datos y el problema en cuestión.
- Explorar y utilizar las capacidades de escalabilidad de KNIME para manejar grandes volúmenes de datos. Aprovechar las funcionalidades de paralelización y distribución de tareas para agilizar el procesamiento.
- Utilizar técnicas de preprocesamiento de datos para mejorar la calidad y la eficacia de la detección de anomalías. Esto puede incluir la normalización de datos, la eliminación de valores atípicos o la reducción de dimensiones.
- Analizar y comprender las características y patrones de los datos antes de aplicar los algoritmos de detección de anomalías. Esto ayudará a interpretar de manera adecuada los resultados y evitar falsos positivos o negativos.
- Utilizar visualizaciones y métricas proporcionadas por KNIME para evaluar y validar los resultados de detección de anomalías. Esto permitirá una interpretación más precisa y una toma de decisiones fundamentada.
La detección de anomalías con KNIME puede resultar desafiante, pero con un buen conocimiento de los algoritmos, habilidades de manejo de datos y análisis adecuado de los resultados, los usuarios podrán superar estos desafíos y obtener resultados más precisos y confiables.
Existe alguna forma de automatizar el proceso de detección de anomalías en KNIME
Sí, existe la forma de automatizar el proceso de detección de anomalías en KNIME. La plataforma ofrece varias herramientas y técnicas que permiten identificar y resolver problemas de forma eficiente.
Una de las formas más comunes de automatizar este proceso es utilizando algoritmos de aprendizaje automático, como el algoritmo de detección de anomalías. Este algoritmo utiliza modelos estadísticos y matemáticos para identificar patrones inusuales en los datos.
Otra forma de automatizar la detección de anomalías en KNIME es utilizando flujos de trabajo. Los flujos de trabajo permiten crear procesos automatizados que pueden ejecutarse de forma secuencial o paralela, lo que facilita la ejecución de tareas repetitivas y la detección de anomalías de forma continua.
Además, KNIME ofrece una amplia gama de extensiones y plugins que simplifican y aceleran el proceso de detección de anomalías. Estas extensiones incluyen algoritmos adicionales, funciones predefinidas y visualizaciones avanzadas que ayudan a identificar y resolver problemas de manera eficiente.
KNIME permite automatizar el proceso de detección de anomalías utilizando algoritmos de aprendizaje automático, flujos de trabajo y extensiones especializadas. Esto ayuda a los usuarios a identificar y resolver problemas de forma efectiva y eficiente en el análisis de datos.
Cuáles son los diferentes algoritmos de detección de anomalías disponibles en KNIME y en qué situaciones se recomienda su uso
KNIME ofrece una amplia gama de algoritmos de detección de anomalías que se adaptan a diferentes situaciones. Uno de los más comunes es el algoritmo de detección de anomalías basado en distancia, que calcula la distancia entre puntos de datos y los compara con un umbral predefinido.
Otro algoritmo es el de detección de anomalías basado en densidad, que identifica áreas de baja densidad en el espacio de datos como anomalías. Este método es especialmente útil para detectar anomalías en datos con distribuciones no uniformes.
Además, KNIME también ofrece el algoritmo de detección de anomalías basado en modelo, que utiliza modelos estadísticos o de aprendizaje automático para identificar patrones anómalos en los datos.
Para situaciones en las que los datos cambian con el tiempo, el algoritmo de detección de anomalías online es una excelente opción. Este algoritmo puede detectar anomalías en tiempo real y ajustar su modelo a medida que llegan nuevos datos.
KNIME ofrece una variedad de algoritmos de detección de anomalías que se adaptan a diferentes situaciones, desde datos estáticos hasta datos en tiempo real. La elección del algoritmo adecuado dependerá de las características de los datos y los objetivos de detección de anomalías.
Qué pasos puedo seguir para evaluar la efectividad de los resultados obtenidos al utilizar KNIME para detectar anomalías
Para evaluar la efectividad de los resultados obtenidos al utilizar KNIME para detectar anomalías, es importante seguir algunos pasos clave. En primer lugar, se recomienda realizar una exploración exhaustiva de los datos utilizando diferentes visualizaciones y técnicas de análisis exploratorio. Esto permitirá identificar posibles patrones o comportamientos inusuales en los datos.
Una vez realizada la exploración inicial, es fundamental seleccionar las variables relevantes para el análisis de detección de anomalías. Esto implica identificar las características más representativas y significativas en el conjunto de datos, descartando aquellas que no aporten información relevante.
A continuación, se debe definir el método de detección de anomalías más adecuado para el problema en cuestión. KNIME ofrece una amplia gama de algoritmos y técnicas de detección de anomalías, como el método de detección por desviación estándar o el algoritmo Local Outlier Factor (LOF).
Una vez seleccionado el método, es necesario aplicarlo al conjunto de datos y evaluar el rendimiento del modelo. Esto implica calcular métricas de evaluación, como la precisión, la sensibilidad y la especificidad, para determinar la capacidad del modelo para detectar anomalías.
Además, se recomienda utilizar técnicas de validación cruzada para garantizar la robustez y generalización del modelo. Esto implica dividir el conjunto de datos en subconjuntos de entrenamiento y prueba, y evaluar el modelo en diferentes particiones para obtener una medida más precisa de su rendimiento.
Finalmente, es importante analizar y revisar los resultados obtenidos. Esto implica identificar y comprender las anomalías detectadas, así como determinar si son genuinas o si pueden atribuirse a errores o falsos positivos del modelo. Este análisis permitirá validar la efectividad de la detección de anomalías realizada con KNIME y tomar las medidas necesarias para corregir cualquier problema o mejorar el modelo.
Cómo puedo visualizar y comunicar los resultados de las detecciones de anomalías realizadas con KNIME de manera efectiva
Visualizar y comunicar los resultados de las detecciones de anomalías realizadas con KNIME de manera efectiva es fundamental para comprender y compartir los hallazgos con otros miembros del equipo. Aquí hay algunos consejos expertos para lograrlo:
1. Gráficos de dispersión:
Utilizar gráficos de dispersión puede ser una forma efectiva de visualizar las anomalías detectadas. Puedes representar los datos normales en un color y las anomalías en otro, lo que ayuda a identificar fácilmente los puntos inusuales.
2. Diagramas de caja y bigotes:
Los diagramas de caja y bigotes son útiles para mostrar la distribución de los datos y resaltar cualquier valor atípico. Puedes utilizar diferentes colores o símbolos para resaltar las anomalías detectadas.
3. Tablas de resumen:
Presentar los resultados en forma de tabla de resumen puede ser útil para identificar rápidamente las anomalías. Puedes incluir el valor de cada dato, su estado normal o anormal y cualquier información adicional relevante.
4. Visualizaciones interactivas:
Crear visualizaciones interactivas utilizando herramientas como KNIME puede ayudar a explorar los datos en detalle. Los usuarios pueden acercar, alejar y filtrar los datos para identificar patrones y anomalías más fácilmente.
5. Informes claros y concisos:
Cuando comuniques los resultados de las detecciones de anomalías, asegúrate de que tu informe sea claro y conciso. Utiliza gráficos, tablas y texto descriptivo para resaltar las principales conclusiones y hallazgos.
6. Comunicación efectiva:
Es importante comunicar los resultados de manera clara y comprensible para el público objetivo. Utiliza un lenguaje sencillo y evita jergas técnicas innecesarias.
Visualizar y comunicar los resultados de las detecciones de anomalías con KNIME de manera efectiva requiere utilizar diferentes técnicas visuales, presentar la información de manera clara y concisa, y adaptar la comunicación al público objetivo. Al seguir estos consejos expertos, podrás transmitir de manera eficiente tus hallazgos y facilitar la toma de decisiones basada en los resultados obtenidos.
Cuáles son los ejemplos de casos de uso más comunes en los que se utiliza KNIME para detectar anomalías en machine learning
KNIME es una poderosa herramienta utilizada en diversos casos de uso para detectar anomalías en el machine learning. Sus capacidades versátiles permiten detectar y prevenir problemas en diferentes industrias y aplicaciones. Algunos ejemplos comunes de casos de uso incluyen la detección de fraudes en transacciones financieras, la detección de intrusiones en sistemas de seguridad, la identificación de patrones anómalos en datos de sensores y la detección de errores en la manufactura y producción.
En el ámbito financiero, KNIME se utiliza para analizar grandes cantidades de datos transaccionales y detectar actividades fraudulentas. Las técnicas de machine learning proporcionadas por KNIME ayudan a identificar patrones inusuales y detectar posibles fraudes antes de que causen daños significativos.
En el campo de la seguridad de la información, KNIME se utiliza para detectar intrusiones y actividades maliciosas en sistemas y redes. Mediante el análisis de registros y datos de eventos, KNIME ayuda a identificar comportamientos anómalos que pueden indicar una violación de seguridad.
En el sector industrial, KNIME es utilizado para supervisar y controlar la calidad de los procesos de producción. El software puede identificar anomalías en los datos de sensores, como la temperatura, la presión y otras variables, lo que permite detectar problemas de manera temprana y evitar costosos tiempos de inactividad.
Además, KNIME es utilizado en investigación médica para identificar patrones anómalos en datos de pacientes que pueden ayudar en el diagnóstico y el tratamiento de enfermedades. La plataforma permite la integración de diferentes fuentes de datos y técnicas de machine learning para obtener resultados más precisos y confiables.
Estos son solo algunos ejemplos de los casos de uso más comunes en los que se utiliza KNIME para detectar anomalías en machine learning. La versatilidad y la capacidad de personalización de la plataforma la convierten en una herramienta invaluable para aquellos que buscan identificar y prevenir problemas en diferentes industrias y aplicaciones.
Existen recursos adicionales, como tutoriales o documentación, que puedan ayudarme a aprender a utilizar KNIME para detectar anomalías
Sí, KNIME ofrece una amplia variedad de recursos adicionales para ayudarte a aprender a utilizar su plataforma para detectar anomalías en el machine learning. Uno de los recursos más útiles son los tutoriales en línea que puedes encontrar en su sitio web oficial. Estos tutoriales te guiarán paso a paso a través de diferentes escenarios de detección de anomalías y te mostrarán cómo utilizar las herramientas y funciones de KNIME de manera efectiva.
Además de los tutoriales, también puedes acceder a la documentación completa de KNIME, que proporciona una explicación detallada de todas las características y funciones disponibles en la plataforma. La documentación es una gran fuente de información para comprender los conceptos básicos de la detección de anomalías y cómo aplicarlos utilizando KNIME.
Adicionalmente, KNIME cuenta con una comunidad activa de usuarios y expertos en detección de anomalías que están dispuestos a ayudarte a través de foros de discusión y grupos de usuarios. Estos espacios son excelentes para realizar preguntas, obtener consejos y compartir experiencias con otros usuarios de KNIME que también están interesados en la detección de anomalías.
Si estás interesado en aprender a utilizar KNIME para detectar anomalías en el machine learning, hay muchos recursos adicionales disponibles que te pueden ayudar en tu proceso de aprendizaje. Desde tutoriales en línea y documentación hasta una comunidad activa de usuarios, KNIME te brinda todas las herramientas que necesitas para convertirte en un experto en la detección de anomalías con su plataforma.
Preguntas frecuentes (FAQ)
1. ¿Qué es KNIME y cómo puedo usarlo para detectar anomalías en datos?
KNIME es una plataforma de código abierto que permite el análisis de datos y la creación de flujos de trabajo de machine learning. Puede utilizar KNIME para detectar anomalías en datos aplicando técnicas como el análisis estadístico y los algoritmos de detección de patrones.
2. ¿Cuál es la importancia de detectar anomalías en machine learning?
La detección de anomalías es fundamental en el campo del machine learning ya que permite identificar puntos de datos inusuales o atípicos que pueden ser indicadores de problemas en los datos o de comportamientos inesperados. Esto es especialmente útil en áreas como la detección de fraudes, el mantenimiento predictivo y la monitorización de sistemas.
3. ¿Cuáles son algunas técnicas comunes para detectar anomalías en datos utilizando KNIME?
Algunas técnicas comunes para detectar anomalías en datos utilizando KNIME incluyen el análisis de desviación estándar, el análisis de valores atípicos, el análisis de frecuencia y el uso de algoritmos de detección de patrones como el DBSCAN (Density-Based Spatial Clustering of Applications with Noise).
4. ¿Cómo puedo evaluar la efectividad de la detección de anomalías en KNIME?
Para evaluar la efectividad de la detección de anomalías en KNIME, puedes utilizar métricas como la precisión, la sensibilidad y la especificidad. Además, puedes comparar los resultados de la detección de anomalías con datos etiquetados previamente para determinar la tasa de falsos positivos y falsos negativos.
5. ¿Qué precauciones debo tomar al utilizar KNIME para detectar anomalías en datos?
Al utilizar KNIME para detectar anomalías en datos, es importante asegurarse de que los datos utilizados sean representativos y estén correctamente preparados. Además, es recomendable realizar pruebas y validaciones rigurosas para asegurarse de que los resultados de la detección de anomalías sean precisos y confiables.
Envía mensajes en negrita a Slack con KNIME: paso a paso

Maximiza tus datos con SinPecadoPreprocesado en KNIME: Guía completa
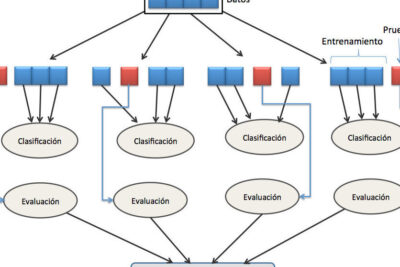
KFold en KNIME: Valida datos con eficacia usando esta herramienta
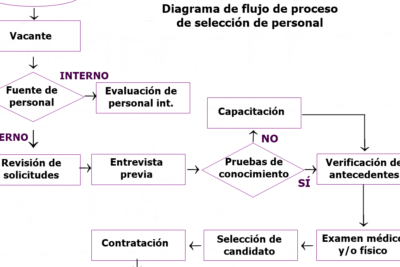
Definir clase objetivo en KNIME: guía paso a paso
Domina los permisos en KNIME y sé un experto en sudo
Aprende cómo usar un nodo para sobredimensionar muestras en KNIME
Aprende a hacer validación cruzada con k-fold en KNIME
Descarta artículos y preposiciones en KNIME: consejos sencillos

Guía experta para leer y escribir archivos Parquet en KNIME
Deja una respuesta
Lo siento, debes estar conectado para publicar un comentario.
Artículos que podrían interesarte