
KFold en KNIME: Valida datos con eficacia usando esta herramienta
Al desarrollar modelos de aprendizaje automático, es crucial evaluar su rendimiento de manera precisa y confiable. Una forma común de hacerlo es mediante la validación cruzada, que divide los datos en conjuntos de entrenamiento y prueba para comprobar la capacidad predictiva del modelo. Sin embargo, realizar este proceso de manera manual puede llevar tiempo y es propenso a errores. Es aquí donde entra en juego la herramienta KFold del software KNIME, que permite realizar la validación cruzada de forma eficiente y sin complicaciones.
Exploraremos en detalle cómo utilizar la herramienta KFold en KNIME para validar nuestros modelos de aprendizaje automático. Veremos cómo configurar los parámetros adecuados, cómo interpretar los resultados y cómo utilizar esta información para mejorar nuestro modelo. Además, descubriremos algunos consejos y trucos para obtener el máximo provecho de KFold y hacer nuestros procesos de validación más efectivos. Si estás buscando una manera fácil y confiable de validar tus modelos, sigue leyendo y descubre cómo KFold en KNIME puede ser la solución que estabas buscando.
¿Qué verás en este artículo?
- Qué es KFold y cómo se utiliza en KNIME
- Cuál es la importancia de validar datos en el análisis de datos
- Qué es KFold y cómo se utiliza en el análisis de datos
- Cuáles son las ventajas de utilizar KFold en comparación con otras técnicas de validación de datos
- Cómo se pueden evitar el sobreajuste y el subajuste al utilizar KFold en KNIME
- Es posible ajustar los parámetros de KFold para obtener mejores resultados
- Cuáles son las mejores prácticas al utilizar KFold en KNIME
- Qué herramientas o algoritmos de KNIME son compatibles con KFold
- Cómo evaluar la eficacia de un modelo utilizando KFold en KNIME
- Existen recursos o tutoriales en línea para aprender más sobre el uso de KFold en KNIME
- Cuáles son las limitaciones o desafíos al utilizar KFold en KNIME
- Preguntas frecuentes (FAQ)
Qué es KFold y cómo se utiliza en KNIME
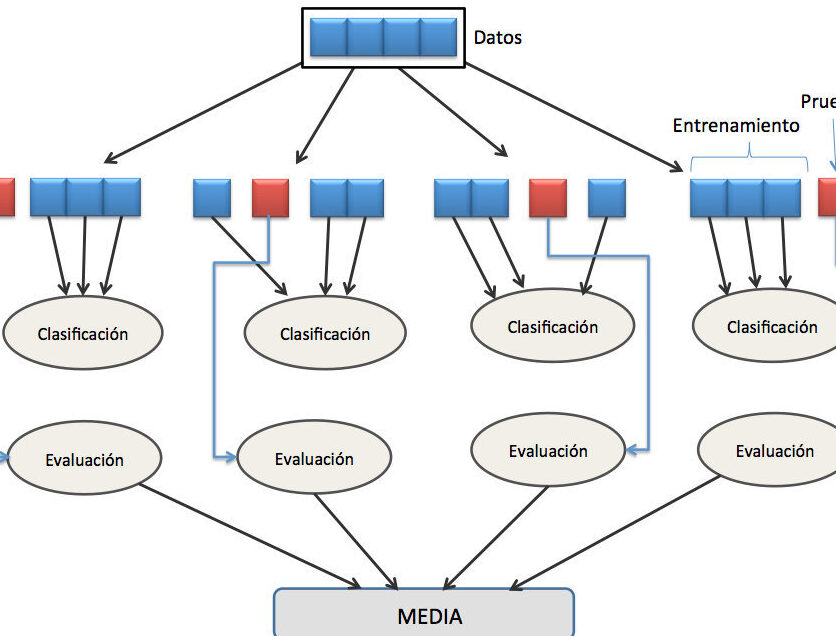
KFold es una técnica de validación cruzada que se utiliza para evaluar el rendimiento de un modelo de aprendizaje automático. Consiste en dividir el conjunto de datos en k subconjuntos o "folds", donde uno de los subconjuntos se utiliza como conjunto de prueba y los restantes como conjunto de entrenamiento. Este proceso se repite k veces, de manera que cada subconjunto se utiliza como conjunto de prueba una vez.
En KNIME, una plataforma de código abierto para el análisis de datos, puedes utilizar el nodo KFold para aplicar esta técnica de validación cruzada. Este nodo te permite especificar el número de folds, así como otras opciones de configuración, como la estratificación de los datos.
Cómo utilizar el nodo KFold en KNIME
Para utilizar el nodo KFold en KNIME, primero debes tener instalada la extensión KNIME Machine Learning y tener tus datos cargados en un nodo de datos. Luego, arrastra y suelta el nodo KFold desde el panel de nodos de KNIME a tu flujo de trabajo.
Una vez que hayas añadido el nodo KFold, debes configurar sus propiedades. Puedes especificar el número de folds utilizando el parámetro "Number of Folds". También puedes optar por habilitar la opción de estratificación, lo que asegurará que la distribución de las clases se mantenga en cada fold.
Una vez configurado el nodo KFold, puedes conectarlo a un nodo de entrenamiento de modelos, como el nodo de entrenamiento de árboles de decisión o el nodo de entrenamiento de regresión logística. De esta manera, el modelo se entrenará y evaluará k veces, utilizando diferentes subconjuntos de datos como conjunto de prueba en cada iteración.
Las ventajas de utilizar KFold en KNIME
El uso de KFold en KNIME tiene varias ventajas. En primer lugar, te permite obtener una evaluación más robusta del rendimiento de tu modelo de aprendizaje automático al utilizar múltiples conjuntos de prueba. Esto ayuda a evitar sesgos o variaciones aleatorias en los resultados.
Otra ventaja es que el nodo KFold en KNIME es altamente configurable. Puedes ajustar el número de folds según tus necesidades y habilitar la estratificación para asegurar una distribución equitativa de las clases en cada fold.
Además, KNIME proporciona una interfaz visual intuitiva, lo que facilita la configuración y visualización de los resultados de KFold. Puedes visualizar las métricas de evaluación, como la precisión o el área bajo la curva ROC, para cada iteración del KFold.
KFold es una técnica de validación cruzada útil en el campo del aprendizaje automático. Al utilizar el nodo KFold en KNIME, puedes aplicar esta técnica de manera eficaz y obtener una evaluación robusta del rendimiento de tus modelos.
Cuál es la importancia de validar datos en el análisis de datos
La validación de datos es una etapa crucial en el análisis de datos. Garantiza que los datos utilizados para realizar inferencias o tomar decisiones sean confiables y precisos. Sin una validación adecuada, existe el riesgo de obtener conclusiones erróneas y tomar decisiones equivocadas.
La validación de datos implica asegurarse de que los datos sean consistentes, correctos y representativos de la población objetivo. Esto implica verificar la integridad de los datos, identificar y corregir posibles errores, eliminar valores atípicos y evaluar la calidad general de los datos.
Además de garantizar la confiabilidad de los datos, la validación también ayuda a identificar posibles sesgos o limitaciones en los datos y a evaluar la calidad de los modelos o algoritmos utilizados en el análisis de datos.
Qué es KFold y cómo se utiliza en el análisis de datos
Cuáles son las ventajas de utilizar KFold en comparación con otras técnicas de validación de datos
KFold es una técnica popular y eficaz para validar modelos de aprendizaje automático. A diferencia de otras técnicas, como la validación cruzada o la validación simple, KFold tiene varias ventajas clave que lo hacen atractivo para los científicos de datos.
En primer lugar, KFold permite una validación más robusta al dividir los datos en k grupos o "folds". Esto significa que cada observación se utiliza tanto para entrenar como para evaluar el modelo, lo que minimiza la posibilidad de sobreajuste y proporciona una estimación más precisa del rendimiento del modelo.
Otra ventaja de KFold es que permite aprovechar al máximo los conjuntos de datos limitados. Al dividir los datos en k grupos, es posible entrenar y evaluar el modelo k veces, utilizando diferentes combinaciones de grupos de entrenamiento y prueba. Esto proporciona una mejor estimación del rendimiento del modelo y ayuda a identificar cualquier variación en el rendimiento entre diferentes combinaciones de datos.
Además, KFold es especialmente útil cuando se trabaja con datos desequilibrados. Al dividir los datos en k grupos de manera estratificada, se garantiza que cada grupo tenga una proporción similar de clases, lo que ayuda a evitar sesgos en el rendimiento del modelo.
KFold ofrece ventajas significativas en términos de robustez, aprovechamiento de conjuntos de datos limitados y manejo de datos desequilibrados. Es una técnica valiosa para validar modelos de aprendizaje automático y debe considerarse como una opción preferida en proyectos de ciencia de datos.
Cómo se pueden evitar el sobreajuste y el subajuste al utilizar KFold en KNIME
El sobreajuste y el subajuste son dos problemas comunes al entrenar modelos de aprendizaje automático. El sobreajuste ocurre cuando el modelo se ajusta demasiado a los datos de entrenamiento y no generaliza bien a nuevos datos. El subajuste, por otro lado, ocurre cuando el modelo no se ajusta lo suficiente a los datos de entrenamiento y no captura las relaciones subyacentes en los datos.
Una forma de evitar estos problemas es utilizando la técnica de validación cruzada KFold en KNIME. KFold divide los datos en k "bolsas" o conjuntos de entrenamiento y prueba. El modelo se entrena en k-1 bolsas y se evalúa en la bolsa restante. Este proceso se repite k veces, cada vez con una bolsa de prueba diferente. Al final, se promedian los resultados para obtener una medida de rendimiento más robusta.
Al utilizar KFold en KNIME, se puede ajustar el hiperparámetro k para controlar la cantidad de bolsas. Un valor común es k=10, lo que significa que los datos se dividen en 10 bolsas. Esto proporciona una estimación más precisa del rendimiento del modelo en datos no vistos.
Beneficios de utilizar KFold en KNIME
Utilizar KFold en KNIME tiene varios beneficios. En primer lugar, ayuda a evitar el sobreajuste y el subajuste al proporcionar una evaluación más robusta del rendimiento del modelo. Esto es especialmente importante cuando se trabaja con conjuntos de datos pequeños o cuando se tiene un desequilibrio entre las clases.
Además, KFold permite aprovechar al máximo los datos disponibles al utilizar todo el conjunto de datos tanto para entrenamiento como para prueba. Esto es especialmente útil cuando se tienen limitaciones de datos y cada muestra es valiosa.
Otro beneficio de utilizar KFold en KNIME es que es fácil de implementar. KNIME proporciona un nodo KFold que se puede utilizar en el flujo de trabajo para dividir los datos en bolsas y realizar la validación cruzada de manera eficiente.
Consideraciones al utilizar KFold en KNIME
Aunque KFold es una técnica poderosa, hay algunas consideraciones a tener en cuenta al utilizarla en KNIME. En primer lugar, es importante asegurarse de que los datos estén bien mezclados antes de aplicar KFold. Esto ayuda a evitar cualquier sesgo en la división de las bolsas y garantiza una evaluación imparcial del modelo.
También es recomendable realizar algún tipo de preprocesamiento de los datos antes de aplicar KFold. Esto puede incluir la normalización de las características, la eliminación de valores atípicos o la selección de características relevantes. Estas etapas de preprocesamiento pueden ayudar a mejorar la calidad de los resultados obtenidos.
Utilizar KFold en KNIME es una forma efectiva de validar datos y evitar el sobreajuste y el subajuste. Al proporcionar una evaluación más robusta del rendimiento del modelo, KFold ayuda a tomar decisiones más informadas sobre qué modelo utilizar en aplicaciones reales.
Es posible ajustar los parámetros de KFold para obtener mejores resultados
Una de las ventajas del método KFold en KNIME es la posibilidad de ajustar los parámetros para obtener mejores resultados en la validación de datos. Al configurar correctamente los parámetros, es posible maximizar la eficacia de esta herramienta y mejorar la precisión de los modelos predictivos.
Por ejemplo, al ajustar el número de pliegues en KFold, se puede obtener una visión más precisa de cómo se comporta el modelo en diferentes divisiones de los datos. Si se utilizan demasiados pliegues, se puede correr el riesgo de sobreajuste, mientras que si se utilizan muy pocos pliegues, se puede perder información valiosa.
Otro parámetro importante a considerar es la forma en que se realiza la división de los datos en pliegues. KNIME permite elegir entre diferentes opciones, como la división aleatoria, la división secuencial o la división estratificada. Cada una de estas opciones tiene sus propias reglas y puede influir en los resultados obtenidos.
Además, es posible ajustar el tamaño de la muestra en cada pliegue. Esto puede ser especialmente útil cuando se trabaja con conjuntos de datos desequilibrados, donde ciertas clases pueden estar subrepresentadas. Al ajustar el tamaño de la muestra en cada pliegue, se pueden obtener estimaciones más precisas del rendimiento del modelo para cada clase.
Ajustar los parámetros de KFold en KNIME es fundamental para obtener resultados más precisos y eficaces en la validación de datos. Al experimentar con diferentes configuraciones y optimizar los parámetros, es posible mejorar la calidad de los modelos predictivos y tomar decisiones más fundamentadas basadas en los resultados obtenidos.
Cuáles son las mejores prácticas al utilizar KFold en KNIME
KFold es una técnica popular en el campo del aprendizaje automático para validar modelos de datos. En este artículo, exploraremos las mejores prácticas al utilizar KFold en KNIME, una plataforma de análisis de datos visual y de código abierto.
1. Dividir los datos de manera equitativa
Al utilizar KFold, es esencial dividir los datos en conjuntos de entrenamiento y prueba de manera equitativa. Esto significa que cada conjunto debe contener una proporción igual de muestras de cada clase, garantizando así una evaluación justa del modelo.
2. Establecer el número adecuado de pliegues
El número de pliegues en KFold determina cuántas veces se dividirán los datos. Un número mayor de pliegues puede brindar una evaluación más precisa del modelo, pero también requiere más tiempo de procesamiento. Es importante encontrar un equilibrio entre precisión y eficiencia.
3. Realizar una validación cruzada anidada
Una técnica de validación cruzada anidada puede proporcionar resultados aún más robustos al utilizar KFold en KNIME. Esta técnica implica repetir el proceso de KFold múltiples veces, alternando entre los conjuntos de entrenamiento y prueba. Esto ayuda a mitigar cualquier sesgo y mejora la generalización del modelo.
4. Considerar la estratificación en los pliegues
En algunos casos, es importante considerar la estratificación al dividir los datos en pliegues con KFold. La estratificación asegura que cada pliegue tenga una proporción similar de muestras de cada clase, lo que es especialmente beneficioso en conjuntos de datos desequilibrados.
5. Evaluar el modelo en cada pliegue
Al utilizar KFold en KNIME, es esencial evaluar el modelo en cada pliegue individualmente. Esto proporciona una medida más precisa del rendimiento general del modelo y permite identificar cualquier variación entre los pliegues.
6. Realizar una validación de resultados
Después de completar el proceso de KFold en KNIME, se recomienda realizar una validación de resultados para evaluar la estabilidad y generalización del modelo. Esto puede incluir métricas como la precisión, la sensibilidad y la especificidad.
KFold es una técnica efectiva para validar modelos de datos en KNIME. Al seguir estas mejores prácticas, puedes garantizar una evaluación precisa y justa de tus modelos, lo que te ayudará a tomar decisiones basadas en datos más sólidas y confiables.
Qué herramientas o algoritmos de KNIME son compatibles con KFold
En KNIME, la herramienta KFold se utiliza comúnmente en combinación con algoritmos de aprendizaje automático supervisado. Algunos de los algoritmos compatibles con KFold incluyen la regresión lineal, la clasificación de árboles de decisión, el algoritmo de vecinos más cercanos y el algoritmo de máquinas de soporte vectorial. Estos algoritmos utilizan el método KFold para dividir los datos en diferentes conjuntos de entrenamiento y prueba, lo que permite una validación cruzada efectiva de los resultados del modelo. Al combinar KFold con estos algoritmos, los usuarios pueden obtener resultados más precisos y confiables al evaluar sus modelos de aprendizaje automático.
Cómo evaluar la eficacia de un modelo utilizando KFold en KNIME
Cuando se trata de evaluar la eficacia de un modelo de machine learning, es esencial utilizar técnicas de validación cruzada. Una de las herramientas más populares y poderosas para realizar esta tarea es KFold en KNIME.
KFold es una técnica de validación cruzada que divide el conjunto de datos en k subconjuntos llamados "folds". Luego, se entrenan y evalúan k modelos diferentes, utilizando cada uno de los folds como conjunto de prueba y el resto de los folds como conjunto de entrenamiento.
Esta técnica es particularmente útil cuando el conjunto de datos es limitado, ya que permite utilizar el máximo de información disponible para entrenar y evaluar el modelo. Además, KFold en KNIME ofrece una implementación sencilla y eficiente de esta técnica.
Cómo implementar KFold en KNIME
Para implementar KFold en KNIME, necesitarás el nodo "Cross Validation Loop Start" y el nodo "Cross Validation Loop End". Estos nodos permiten definir el número de folds y la métrica de evaluación que deseas utilizar.
Primero, conecta el nodo de inicio al nodo de fin y define el número de folds deseados. Luego, conecta estos nodos al flujo de trabajo principal y configura el modelo y los nodos de evaluación dentro del bucle de validación cruzada.
Es importante destacar que KNIME ofrece una amplia gama de nodos para construir y evaluar modelos de machine learning, por lo que podrás utilizar diferentes algoritmos y métricas de evaluación según tus necesidades.
Ventajas de utilizar KFold en KNIME
Existen varias ventajas al utilizar KFold en KNIME para evaluar la eficacia de un modelo:
- Permite aprovechar al máximo el conjunto de datos disponible, especialmente cuando este es limitado.
- Proporciona una manera eficiente y sencilla de implementar la validación cruzada.
- Permite comparar múltiples modelos y seleccionar el más eficaz.
- Facilita la identificación de problemas de sobreajuste o subajuste en el modelo.
KFold en KNIME es una herramienta poderosa para evaluar la eficacia de modelos de machine learning. Con su fácil implementación y sus ventajas significativas, es una opción recomendada para cualquier proyecto de analítica de datos.
Existen recursos o tutoriales en línea para aprender más sobre el uso de KFold en KNIME
Si estás interesado en aprender más sobre cómo utilizar KFold en KNIME, estás de suerte. Hay una amplia gama de recursos y tutoriales en línea disponibles que te guiarán a través del proceso paso a paso.
Estos recursos te proporcionarán información detallada sobre cómo implementar KFold en KNIME, así como consejos y trucos para obtener los mejores resultados. Además, también te mostrarán ejemplos prácticos para que puedas ver cómo se aplica KFold en situaciones reales.
Ya sea que prefieras tutoriales en video, artículos escritos o incluso cursos en línea completos, encontrarás una gran cantidad de opciones para satisfacer tus necesidades de aprendizaje. No dudes en explorar estos recursos y sumergirte en el apasionante mundo de KFold en KNIME.
Cuáles son las limitaciones o desafíos al utilizar KFold en KNIME
Al utilizar KFold en KNIME, es importante tener en cuenta algunas limitaciones o desafíos que pueden surgir. Uno de los desafíos más comunes es la necesidad de seleccionar el número adecuado de subdivisiones (k) para el conjunto de datos. Si k es muy pequeño, el modelo puede no ser lo suficientemente generalizado, mientras que si k es demasiado grande, el proceso de validación cruzada puede volverse costoso en términos de tiempo de ejecución.
Otro desafío está relacionado con el desequilibrio de clases en el conjunto de datos. Si algunas clases están sobre o subrepresentadas, puede haber una distribución desigual de muestras en las divisiones, lo que puede afectar negativamente la precisión de la evaluación del modelo. Para abordar este problema, es posible aplicar técnicas de muestreo estratificado durante el proceso de subdivisión.
Además, la capacidad de KNIME para manejar grandes volúmenes de datos puede verse limitada al utilizar KFold, ya que el proceso de subdivisión implica la creación de múltiples particiones del conjunto de datos, lo que puede requerir una cantidad significativa de memoria y poder de procesamiento.
Finalmente, es importante considerar que KFold asume que los datos son independientes y distribuidos de manera idéntica. Sin embargo, en situaciones en las que los datos presentan una estructura temporal o espacial, el uso de KFold puede no ser apropiado, y se deben considerar otras técnicas de validación cruzada.
Preguntas frecuentes (FAQ)
¿Qué es KFold en KNIME?
KFold es una técnica de validación cruzada utilizada en KNIME para evaluar de manera efectiva el rendimiento de un modelo de aprendizaje automático.
¿Cómo funciona KFold en KNIME?
KFold divide el dataset en k partes iguales, utiliza k-1 partes como conjunto de entrenamiento y la parte restante como conjunto de prueba. Este proceso se repite k veces y se obtiene un promedio de las métricas de evaluación para evaluar el modelo.
¿Cuál es la importancia de usar KFold en KNIME?
KFold ayuda a evitar problemas de sobreajuste o subajuste al evaluar un modelo de aprendizaje automático, ya que utiliza múltiples conjuntos de entrenamiento y prueba para obtener una evaluación más precisa.
¿Cómo se configura KFold en KNIME?
En KNIME, se puede configurar KFold utilizando el nodo "Cross Validation Loop Start". Aquí se puede especificar el número de particiones y otras opciones de configuración relacionadas.
¿Cuáles son las métricas de evaluación que se pueden obtener usando KFold en KNIME?
Al usar KFold en KNIME, se pueden obtener métricas de evaluación como la precisión, la sensibilidad, la especificidad y el área bajo la curva ROC, entre otras.
Envía mensajes en negrita a Slack con KNIME: paso a paso

Maximiza tus datos con SinPecadoPreprocesado en KNIME: Guía completa
Definir clase objetivo en KNIME: guía paso a paso
Domina los permisos en KNIME y sé un experto en sudo
Aprende cómo usar un nodo para sobredimensionar muestras en KNIME
Aprende a hacer validación cruzada con k-fold en KNIME
Descarta artículos y preposiciones en KNIME: consejos sencillos

Guía experta para leer y escribir archivos Parquet en KNIME
KNIME: Crea un bucle simple para leer varios archivos
Deja una respuesta
Lo siento, debes estar conectado para publicar un comentario.
Artículos que podrían interesarte