
Validación cruzada en KNIME para nodos: Todo lo que necesitas saber
KNIME es una plataforma de análisis de datos y creación de modelos que se utiliza en una amplia variedad de industrias y campos de estudio. Una de las técnicas más importantes y utilizadas en KNIME es la validación cruzada, que es fundamental para evaluar la precisión y el rendimiento de los modelos de aprendizaje automático. La validación cruzada nos permite estimar cómo se comportará un modelo en datos no vistos, lo que nos ayuda a tomar decisiones más informadas y a mejorar nuestros modelos.
Exploraremos en detalle cómo usar la validación cruzada en KNIME para nodos. Veremos los conceptos básicos de la validación cruzada y cómo se implementa en KNIME. También discutiremos las ventajas y desventajas de la validación cruzada y daremos ejemplos prácticos de su uso en KNIME. Si estás interesado en mejorar tus modelos de aprendizaje automático y quieres aprender a usar la validación cruzada en KNIME de manera efectiva, ¡sigue leyendo!
¿Qué verás en este artículo?
- Qué es la validación cruzada y por qué es importante en KNIME
- Cuáles son los beneficios de utilizar la validación cruzada en KNIME
- Cuál es el proceso paso a paso para realizar una validación cruzada en KNIME
- Cuáles son los diferentes métodos de validación cruzada disponibles en KNIME
- Cómo se pueden utilizar los resultados de la validación cruzada en KNIME para mejorar los modelos predictivos
- Cuáles son las mejores prácticas a seguir al realizar una validación cruzada en KNIME
- Existen herramientas o plugins adicionales en KNIME que faciliten la realización de la validación cruzada
-
Cuáles son los errores comunes que se deben evitar al realizar una validación cruzada en KNIME
- No definir correctamente el número de divisiones
- No aleatorizar los datos antes de la validación cruzada
- No tener en cuenta el desequilibrio de clases
- No considerar la selección de características
- No realizar una validación cruzada anidada
- No analizar adecuadamente los resultados
- No tener en cuenta el tiempo de ejecución
- No documentar adecuadamente el proceso
- Qué consideraciones se deben tener en cuenta al elegir el número de folds en la validación cruzada en KNIME
- Es posible realizar una validación cruzada en KNIME utilizando diferentes algoritmos de machine learning
- Qué métricas de evaluación se pueden utilizar para medir el rendimiento de un modelo en la validación cruzada en KNIME
- Cuáles son los desafíos y limitaciones de la validación cruzada en KNIME y cómo se pueden superar
- Cuál es la relación entre la validación cruzada y el sobreajuste en los modelos de machine learning en KNIME
- Cómo se pueden interpretar los resultados obtenidos de la validación cruzada en KNIME para tomar decisiones informadas sobre los modelos predictivos
- Qué otras estrategias de validación se pueden combinar con la validación cruzada en KNIME para obtener resultados más robustos
- Preguntas frecuentes (FAQ)
Qué es la validación cruzada y por qué es importante en KNIME
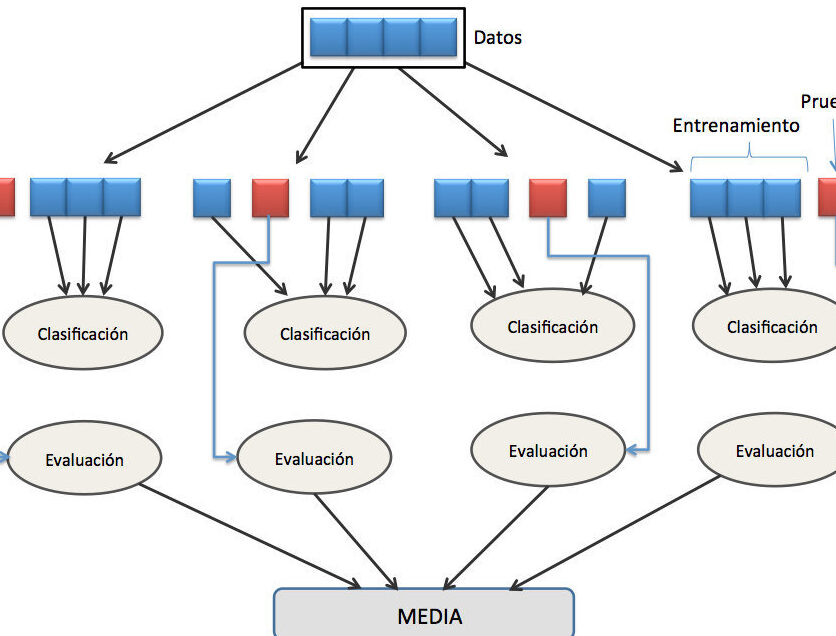
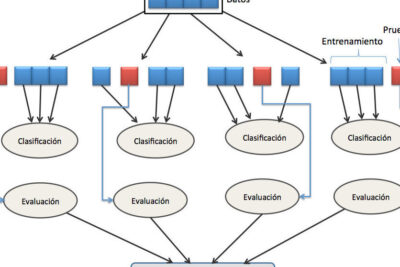
La validación cruzada es una técnica utilizada en el aprendizaje automático para evaluar el rendimiento de un modelo predictivo. En KNIME, esta técnica se aplica a través de nodos especializados. La validación cruzada es fundamental porque permite obtener una estimación más precisa y confiable del desempeño del modelo al evaluarlo en diferentes subconjuntos de datos. Esto evita problemas como el sobreajuste y garantiza que el modelo sea generalizable a nuevos datos. En KNIME, existen varios nodos que facilitan la implementación de la validación cruzada, como el nodo "Cross Validation Loop Start" y el nodo "Cross Validation Loop End".
Cuáles son los beneficios de utilizar la validación cruzada en KNIME
La validación cruzada es una técnica crucial en el análisis de datos para evaluar la precisión de un modelo y evitar el sobreajuste. En KNIME, la validación cruzada se puede realizar utilizando diferentes nodos que proporcionan diferentes métodos, como k-fold, leave-one-out, stratified, entre otros.
Los beneficios de utilizar la validación cruzada en KNIME son variados. En primer lugar, permite una evaluación más rigurosa del modelo al utilizar múltiples conjuntos de datos de prueba y entrenamiento. Esto ayuda a detectar problemas de sobreajuste y a evaluar la capacidad del modelo para generalizar a datos no vistos.
Otro beneficio importante es que la validación cruzada permite tener una estimación más precisa del rendimiento del modelo, ya que utiliza todos los datos disponibles para entrenar y probar el modelo. Esto es especialmente útil cuando se tiene un conjunto de datos pequeño.
Además, la validación cruzada en KNIME facilita la comparación de diferentes modelos y configuraciones. Al utilizar la misma estrategia de validación cruzada para todos los modelos, se pueden obtener métricas de evaluación comparables y tomar decisiones informadas sobre qué modelo es el más adecuado.
La validación cruzada en KNIME es una herramienta poderosa para evaluar y comparar modelos de manera rigurosa. Proporciona una estimación precisa del rendimiento del modelo y ayuda a detectar problemas de sobreajuste. Si quieres obtener resultados más confiables y tomar decisiones informadas en tu análisis de datos, la validación cruzada en KNIME es una técnica que vale la pena usar.
Cuál es el proceso paso a paso para realizar una validación cruzada en KNIME
La validación cruzada es una técnica fundamental en el proceso de evaluación de modelos de aprendizaje automático. En KNIME, realizar una validación cruzada es sencillo y se puede hacer en unos pocos pasos.
Paso 1: Preparar los datos
Antes de empezar con la validación cruzada, es importante preparar los datos de la manera adecuada. Esto implica limpiar los datos, seleccionar las variables relevantes y dividir los datos en conjuntos de entrenamiento y prueba.
Paso 2: Configurar el nodo Cross Validation Loop Start
En KNIME, el nodo principal para realizar la validación cruzada es el Cross Validation Loop Start. Este nodo se encarga de dividir los datos en k pliegues (folds) y ejecutar el flujo de trabajo para cada pliegue.
Paso 3: Configurar el modelo de aprendizaje automático
Antes de configurar el modelo de aprendizaje automático, es importante tener claro cuál es el objetivo del análisis y qué tipo de modelo se va a utilizar. KNIME ofrece una amplia gama de nodos para diferentes algoritmos de aprendizaje automático, como árboles de decisión, regresión logística y máquinas de soporte vectorial.
Paso 4: Configurar el nodo Cross Validation Loop End
Después de configurar el modelo de aprendizaje automático, es necesario configurar el nodo Cross Validation Loop End. Este nodo se encarga de combinar los resultados de cada pliegue y generar las métricas de evaluación, como la precisión, la sensibilidad y la especificidad.
Paso 5: Evaluar el rendimiento del modelo
Una vez que se ha completado el proceso de validación cruzada, es importante evaluar el rendimiento del modelo. KNIME ofrece una variedad de herramientas y nodos para visualizar y analizar los resultados, como gráficos de dispersión, matrices de confusión y curvas ROC.
Realizar una validación cruzada en KNIME implica preparar los datos, configurar el nodo Cross Validation Loop Start, configurar el modelo de aprendizaje automático, configurar el nodo Cross Validation Loop End y evaluar el rendimiento del modelo. Con estos pasos, podrás realizar una validación cruzada efectiva en KNIME y obtener resultados confiables para tus modelos de aprendizaje automático.
Cuáles son los diferentes métodos de validación cruzada disponibles en KNIME
En KNIME, existen diferentes métodos de validación cruzada disponibles que te permiten evaluar la robustez y el rendimiento de tus modelos. Algunos de los métodos más comunes incluyen la validación cruzada k-fold, la validación cruzada leave-one-out y la validación cruzada estratificada.
La validación cruzada k-fold divide el conjunto de datos en k pliegues o grupos, donde cada grupo se utiliza como conjunto de prueba y el resto se utiliza como conjunto de entrenamiento. Este proceso se repite k veces y los resultados se promedian para obtener una estimación más precisa del rendimiento del modelo.
La validación cruzada leave-one-out es un método en el que se entrena el modelo en todos los casos excepto en uno, que se utiliza como conjunto de prueba. Este proceso se repite para todos los casos y se obtienen las métricas de rendimiento promedio.
Por otro lado, la validación cruzada estratificada se utiliza cuando se desea mantener la proporción de clases en cada pliegue. Esto es especialmente útil cuando hay un desequilibrio de clases en el conjunto de datos.
Cómo se pueden utilizar los resultados de la validación cruzada en KNIME para mejorar los modelos predictivos
La validación cruzada es una técnica ampliamente utilizada en el aprendizaje automático para evaluar el rendimiento de un modelo predictivo. KNIME, una plataforma de análisis de datos, ofrece nodos especialmente diseñados para implementar la validación cruzada en tus proyectos.
La validación cruzada en KNIME te permite dividir tus datos en múltiples conjuntos de entrenamiento y prueba, lo que te ayuda a evaluar cómo se comporta tu modelo en diferentes escenarios. Esto es útil para identificar posibles problemas de sobreajuste o subajuste y te permite ajustar tus modelos para obtener predicciones más precisas.
Una vez que hayas ejecutado la validación cruzada en KNIME, podrás obtener varios resultados útiles para mejorar tus modelos predictivos. Por ejemplo, podrás obtener medidas como la precisión, la sensibilidad y la especificidad, que te darán una idea del rendimiento general de tu modelo.
Además, podrás visualizar los resultados de la validación cruzada en KNIME mediante gráficos y tablas. Estas visualizaciones te permitirán identificar patrones y tendencias en tus datos, lo que te ayudará a comprender mejor el comportamiento de tu modelo y a tomar decisiones más informadas.
Utilizar los resultados de la validación cruzada en KNIME te brinda una ventaja significativa al desarrollar modelos predictivos. Al evaluar tu modelo en múltiples escenarios y obtener medidas de rendimiento precisas, podrás ajustar y mejorar tus modelos para lograr predicciones más acertadas.
Cuáles son las mejores prácticas a seguir al realizar una validación cruzada en KNIME
La validación cruzada es una técnica esencial en el análisis de datos para evaluar el rendimiento de un modelo. En KNIME, existen varias prácticas recomendadas que se deben seguir al realizar una validación cruzada.
En primer lugar, es importante seleccionar el número adecuado de particiones o "folds" para la validación cruzada. Esto dependerá del tamaño del conjunto de datos y de la complejidad del modelo. Generalmente se recomienda utilizar de 5 a 10 folds para obtener resultados confiables.
Otra práctica recomendada es utilizar una estratificación adecuada al dividir el conjunto de datos en folds. Esto significa que las proporciones de las clases en cada fold deben ser similares a las proporciones en el conjunto de datos original. Esto ayuda a evitar sesgos y proporciona una evaluación más precisa del modelo.
Además, es importante establecer una semilla aleatoria para garantizar la reproducibilidad de los resultados. Esto significa que se debe fijar una semilla antes de realizar la validación cruzada, de modo que los resultados puedan ser replicados en futuros análisis.
En KNIME, existen varios nodos específicos para realizar la validación cruzada, como el nodo "Cross Validation Loop Start" y el nodo "Cross Validation Loop End". Estos nodos facilitan la configuración y ejecución de la validación cruzada en un flujo de trabajo de KNIME.
Al realizar una validación cruzada en KNIME, es importante seguir las mejores prácticas, como seleccionar el número adecuado de folds, utilizar una estratificación adecuada y establecer una semilla aleatoria. Estas prácticas ayudarán a obtener resultados confiables y reproducibles en el análisis de datos.
Existen herramientas o plugins adicionales en KNIME que faciliten la realización de la validación cruzada
Sí, en KNIME existen herramientas y plugins adicionales que facilitan la realización de la validación cruzada. Estas herramientas permiten a los usuarios realizar de manera más eficiente y efectiva la validación cruzada en sus flujos de trabajo. Un ejemplo de esto es el nodo "Cross Validation Loop Start" que se encuentra dentro del grupo de nodos "Data Generation". Este nodo permite al usuario definir el número de repeticiones y la partición del conjunto de datos en cada repetición.
Otro ejemplo es el nodo "Cross Validation Loop End" que se encuentra dentro del grupo de nodos "Data Generation". Este nodo permite al usuario recuperar los pliegues de validación cruzada generados en el nodo de inicio y usarlos en los nodos posteriores del flujo de trabajo. Esto facilita la evaluación y comparación de diferentes modelos de aprendizaje automático en el proceso de validación cruzada.
Además de estos nodos, existen otros plugins y extensiones disponibles en KNIME que ofrecen funcionalidades adicionales para la validación cruzada. Estas extensiones pueden incluir algoritmos de validación cruzada personalizados, métricas de evaluación específicas y visualizaciones interactivas para analizar los resultados de la validación cruzada. Estas herramientas adicionales brindan a los usuarios más flexibilidad y opciones al realizar la validación cruzada en KNIME.
Cuáles son los errores comunes que se deben evitar al realizar una validación cruzada en KNIME
Realizar una validación cruzada en KNIME es una técnica esencial para evaluar y ajustar modelos de machine learning. Sin embargo, existen ciertos errores comunes que se deben evitar al llevar a cabo este proceso. A continuación, mencionaremos algunos de ellos:
No definir correctamente el número de divisiones
Es importante determinar cuántas divisiones se utilizarán en la validación cruzada. Si el valor es muy alto, el modelo puede sobreajustarse a los datos y no generalizar correctamente. Por otro lado, si es muy bajo, la estimación del rendimiento del modelo puede ser inexacta. Se recomienda encontrar un equilibrio entre el número de divisiones y la cantidad de datos disponibles.
No aleatorizar los datos antes de la validación cruzada
Es fundamental asegurarse de que los datos estén aleatorizados antes de realizar la validación cruzada. De lo contrario, los resultados pueden verse sesgados y no representarán adecuadamente el rendimiento general del modelo. KNIME ofrece herramientas para aleatorizar los datos antes de la validación cruzada, asegúrate de utilizarlas correctamente.
No tener en cuenta el desequilibrio de clases
En algunos casos, los conjuntos de datos pueden tener clases desequilibradas, es decir, una clase puede tener muchos más ejemplos que otras. Si esto ocurre, es importante utilizar técnicas de validación cruzada específicas, como la estratificación, para asegurarse de que todas las clases estén representadas adecuadamente durante el proceso de validación.
No considerar la selección de características
La selección de características es un paso crucial en el proceso de modelado. Es importante tener en cuenta qué características se están utilizando durante la validación cruzada. Si se utilizan todas las características disponibles, es posible que el modelo esté sobreajustado y no pueda generalizar bien. Se recomienda realizar un análisis de características y seleccionar las más relevantes para el problema en cuestión.
No realizar una validación cruzada anidada
La validación cruzada anidada es una técnica que permite obtener una estimación más precisa del rendimiento del modelo. Consiste en realizar una validación cruzada interna para la selección de hiperparámetros y una validación cruzada externa para evaluar el rendimiento final del modelo. No realizar una validación cruzada anidada puede llevar a una selección de hiperparámetros subóptima y a una estimación inexacta del rendimiento.
No analizar adecuadamente los resultados
Una vez realizada la validación cruzada, es importante analizar adecuadamente los resultados obtenidos. Esto incluye examinar medidas de rendimiento como precisión, recall y F1-score, así como visualizar curvas de aprendizaje y matrices de confusión. Analizar los resultados te permitirá comprender mejor el rendimiento del modelo y realizar mejoras o ajustes si es necesario.
No tener en cuenta el tiempo de ejecución
Al realizar una validación cruzada en KNIME, es importante tener en cuenta el tiempo de ejecución del proceso. Si el tiempo de ejecución es excesivamente largo, puede ser necesario considerar técnicas de reducción de dimensionalidad o utilizar algoritmos más eficientes. Si el tiempo de ejecución es muy corto, es posible que la validación cruzada no esté proporcionando una evaluación precisa del modelo. Encuentra un equilibrio que se ajuste a tus necesidades y recursos disponibles.
No documentar adecuadamente el proceso
Finalmente, es esencial documentar adecuadamente el proceso de validación cruzada realizado en KNIME. Esto incluye registrar los parámetros utilizados, los resultados obtenidos, las técnicas empleadas y cualquier otro detalle relevante. La documentación adecuada te permitirá reproducir los resultados en el futuro y comunicar de manera clara y precisa tus hallazgos a otros investigadores o profesionales.
Qué consideraciones se deben tener en cuenta al elegir el número de folds en la validación cruzada en KNIME
Al realizar una validación cruzada en KNIME, es importante tener en cuenta varias consideraciones al elegir el número de folds que se utilizarán. El número de folds determina la división de los datos en conjuntos de entrenamiento y prueba, lo que afecta directamente a la precisión del modelo. Un número demasiado bajo de folds puede resultar en un modelo sobreajustado, mientras que un número demasiado alto puede aumentar el tiempo de ejecución y la complejidad del análisis. Por lo tanto, es necesario encontrar un equilibrio adecuado.
Una forma común de determinar el número de folds es utilizar una estrategia de "k-fold cross-validation". Aquí, k representa el número de folds en el análisis. Los valores típicos para k suelen ser 5, 10 o 20, aunque esto puede variar según el tamaño del conjunto de datos y el objetivo del análisis. Un número más alto de folds suele ser preferible cuando el conjunto de datos es pequeño, ya que proporciona una mejor estimación de la precisión del modelo.
Por otro lado, un número más bajo de folds puede ser adecuado cuando se trata de conjuntos de datos grandes, ya que reduce el tiempo de ejecución y la complejidad del análisis. Sin embargo, es importante tener en cuenta que un número bajo de folds puede llevar a una estimación poco fiable de la precisión del modelo, especialmente si el conjunto de datos es heterogéneo o desbalanceado.
Otra consideración importante es la cantidad de datos disponibles. Si el conjunto de datos es pequeño, puede resultar difícil dividirlos en un número alto de folds sin perder la representatividad de los datos. En estos casos, es posible utilizar técnicas como la estratificación, que asegura que cada fold contenga una proporción similar de datos de cada clase. Esto es especialmente crucial en problemas de clasificación, donde es importante evaluar la capacidad del modelo para generalizar en diferentes clases.
Al elegir el número de folds en la validación cruzada en KNIME, es fundamental considerar el tamaño del conjunto de datos, la precisión deseada y el tiempo de ejecución disponible. Un número más alto de folds suele ser preferible para conjuntos de datos pequeños, mientras que un número más bajo puede ser adecuado para conjuntos de datos grandes. Además, es importante tener en cuenta técnicas adicionales, como la estratificación, para garantizar la representatividad de los datos en cada fold.
Es posible realizar una validación cruzada en KNIME utilizando diferentes algoritmos de machine learning
La validación cruzada es una técnica comúnmente utilizada en machine learning para evaluar el rendimiento de un modelo. KNIME, una herramienta de código abierto para análisis de datos y creación de flujos de trabajo, ofrece la posibilidad de realizar validación cruzada utilizando diferentes algoritmos.
La validación cruzada es especialmente útil cuando se tiene un conjunto de datos limitado, ya que permite maximizar el uso de los datos para entrenar y evaluar el modelo. Con KNIME, es posible realizar una validación cruzada utilizando diferentes esquemas, como el esquema k-fold o leave-one-out.
El esquema k-fold divide el conjunto de datos en k subconjuntos iguales, donde k-1 subconjuntos se utilizan para entrenar el modelo y el subconjunto restante se utiliza para evaluar el rendimiento del modelo. Este proceso se repite k veces, utilizando cada subconjunto como conjunto de prueba exactamente una vez.
Por otro lado, el esquema leave-one-out es similar al esquema k-fold, pero con k igual al tamaño del conjunto de datos. Esto significa que se entrena el modelo en todos los datos excepto en una única instancia, que se utiliza para evaluar el rendimiento del modelo.
Para utilizar la validación cruzada en KNIME, primero debes seleccionar el algoritmo de machine learning que deseas utilizar. KNIME ofrece una amplia gama de algoritmos, como regresión logística, árboles de decisión, SVM y redes neuronales, entre otros.
Luego, puedes arrastrar y soltar el nodo correspondiente al algoritmo seleccionado en el flujo de trabajo de KNIME. A continuación, debes conectar los nodos de entrada y salida adecuados, y configurar los parámetros del algoritmo según tus necesidades.
Ahora, para realizar la validación cruzada, simplemente debes arrastrar y soltar el nodo "Cross Validator" en tu flujo de trabajo. Este nodo te permite configurar el esquema de validación cruzada que deseas utilizar, así como el número de folds en el caso del esquema k-fold.
Una vez que hayas configurado el nodo "Cross Validator", puedes conectarlo al nodo del algoritmo de machine learning. Al ejecutar el flujo de trabajo, KNIME realizará la validación cruzada utilizando el algoritmo seleccionado y te proporcionará métricas de evaluación del rendimiento, como precisión, recall y F1-score.
La validación cruzada en KNIME es una técnica poderosa para evaluar el rendimiento de un modelo de machine learning. Con la capacidad de utilizar diferentes algoritmos y esquemas de validación cruzada, KNIME ofrece a los usuarios una herramienta versátil para el análisis de datos y la construcción de modelos precisos.
Qué métricas de evaluación se pueden utilizar para medir el rendimiento de un modelo en la validación cruzada en KNIME
La validación cruzada es una técnica ampliamente utilizada para evaluar el rendimiento de un modelo en machine learning. En KNIME, existen diferentes métricas de evaluación que se pueden utilizar para medir el rendimiento de un modelo durante la validación cruzada.
Una de las métricas más comunes es la precisión (accuracy), que mide la proporción de observaciones correctamente clasificadas en relación con el total de observaciones. Es una métrica útil cuando las clases están balanceadas.
Otra métrica importante es la precisión ponderada (weighted precision), que tiene en cuenta el desequilibrio de clases al asignar un peso a cada clase.
La recall, o sensibilidad (recall), es otra métrica relevante de la validación cruzada. Mide la proporción de observaciones positivas clasificadas correctamente en relación con el total de observaciones positivas.
Además de estas métricas, también se pueden utilizar otras como la F-measure, que combina la precisión y la recall en una sola medida, y el área bajo la curva ROC (AUC-ROC), que mide la calidad del modelo para clasificar correctamente observaciones positivas y negativas.
Es importante seleccionar las métricas adecuadas para evaluar el rendimiento del modelo según el problema específico y las características de los datos. KNIME ofrece una amplia gama de nodos de evaluación que permiten calcular fácilmente estas métricas durante la validación cruzada.
Cuáles son los desafíos y limitaciones de la validación cruzada en KNIME y cómo se pueden superar
La validación cruzada es una técnica ampliamente utilizada en el aprendizaje automático para evaluar y seleccionar modelos de manera más precisa. Sin embargo, también presenta algunos desafíos y limitaciones que deben ser considerados.
1. Tamaño del conjunto de datos
Uno de los desafíos de la validación cruzada es que requiere un conjunto de datos lo suficientemente grande como para dividirlo en diferentes subconjuntos. Si el conjunto de datos es pequeño, puede llevar a una división desigual y una mala estimación de la precisión del modelo.
2. Sesgo y varianza
La validación cruzada puede sufrir de sesgo y varianza. El sesgo ocurre cuando el modelo subestima o sobreestima sistemáticamente los valores reales. La varianza, por otro lado, ocurre cuando el modelo es muy sensible a las variaciones en los datos de entrenamiento. Ambos pueden afectar la precisión de la validación cruzada.
3. Configuración del número de folds
El número de folds utilizado en la validación cruzada es una configuración clave que puede afectar la precisión de los resultados. Si se utilizan muy pocos folds, puede haber una alta varianza. Por otro lado, si se utilizan demasiados folds, puede haber un alto sesgo.
4. Escasez de datos en determinadas clases
Si el conjunto de datos presenta una escasez de datos en alguna clase o categoría, puede llevar a una mala estimación de la precisión del modelo. Esto se debe a que algunas clases pueden no estar representadas adecuadamente en los diferentes subconjuntos utilizados en la validación cruzada.
Cómo superar los desafíos y limitaciones
Existen diferentes enfoques y técnicas que se pueden utilizar para superar los desafíos y limitaciones de la validación cruzada en KNIME:
- Utilizar técnicas de remuestreo, como el remuestreo estratificado, para garantizar que todas las clases estén representadas adecuadamente en los subconjuntos utilizados en la validación cruzada.
- Realizar una evaluación exhaustiva de diferentes configuraciones del número de folds para encontrar la configuración óptima que minimice tanto el sesgo como la varianza.
- Utilizar técnicas de validación cruzada modificadas, como la validación cruzada en bloques o la validación cruzada repetida, para abordar problemas específicos de sesgo, varianza o escasez de datos.
La validación cruzada en KNIME es una herramienta valiosa para evaluar y seleccionar modelos de manera más precisa. Sin embargo, también presenta desafíos y limitaciones que deben ser considerados y abordados adecuadamente para obtener resultados confiables.
Cuál es la relación entre la validación cruzada y el sobreajuste en los modelos de machine learning en KNIME
La validación cruzada es una técnica fundamental en el campo del machine learning en KNIME para evaluar el rendimiento de los modelos de forma más precisa. Al entrenar un modelo en un conjunto de datos, existe el riesgo de sobreajuste, lo que significa que el modelo se ajusta demasiado a los datos de entrenamiento y no generaliza bien con nuevos datos. La validación cruzada ayuda a abordar este problema dividiendo el conjunto de datos en varios subconjuntos y evaluando el modelo en cada uno de ellos. Esto permite obtener una estimación más fiable del rendimiento del modelo y detectar posibles problemas de sobreajuste.
Cómo funciona la validación cruzada en KNIME
La validación cruzada en KNIME se lleva a cabo utilizando nodos específicos. Uno de los nodos más comunes es el nodo "Cross Validation Loop Start". Este nodo divide el conjunto de datos en K subconjuntos, donde K es el número especificado por el usuario. Luego, el nodo "Cross Validation Loop End" entrena el modelo en cada uno de estos subconjuntos y evalúa su rendimiento. El resultado final es un promedio de las métricas de rendimiento obtenidas en cada iteración.
Beneficios de la validación cruzada en KNIME
La validación cruzada en KNIME ofrece varios beneficios. En primer lugar, permite una evaluación más precisa del rendimiento del modelo al tener en cuenta diferentes subconjuntos de datos. Esto ayuda a identificar posibles problemas de sobreajuste y seleccionar el mejor modelo. Además, la validación cruzada en KNIME también permite ajustar los parámetros del modelo de manera más efectiva, ya que se puede evaluar el rendimiento en diferentes combinaciones. Esto ayuda a encontrar la configuración óptima para maximizar el rendimiento del modelo en datos no vistos.
Consideraciones al utilizar la validación cruzada en KNIME
Al utilizar la validación cruzada en KNIME, es importante tener en cuenta algunas consideraciones. En primer lugar, la selección adecuada del valor de K es crucial. Un K demasiado pequeño puede generar estimaciones sesgadas, mientras que un K demasiado grande puede resultar en un mayor costo computacional. Además, es importante tener en cuenta que la validación cruzada puede ser computacionalmente intensiva, especialmente para conjuntos de datos grandes. Por lo tanto, es recomendable utilizar técnicas de validación cruzada eficientes y optimizar los recursos computacionales según sea necesario.
K-Fold Cross Validation: Este método divide los datos en K subconjuntos y utiliza uno de los subconjuntos como conjunto de validación mientras entrena el modelo en los K-1 subconjuntos restantes. Este proceso se repite K veces, utilizando un subconjunto diferente como conjunto de validación en cada iteración.Leave-One-Out Cross Validation: Este método es una variante de K-Fold Cross Validation donde K es igual al número de instancias en el conjunto de datos. En cada iteración, se selecciona una única instancia como conjunto de validación y se entrena el modelo en todas las demás instancias.Stratified Cross Validation: Este método es especialmente útil cuando el conjunto de datos está desequilibrado en términos de las clases objetivo. Asegura que cada subconjunto de validación tenga una proporción similar de instancias de cada clase.
La validación cruzada es una técnica esencial en KNIME para evaluar el rendimiento de los modelos de machine learning y abordar el problema del sobreajuste. Permite una evaluación más precisa del rendimiento del modelo y ayuda en la selección de la mejor configuración de parámetros. Sin embargo, es importante tener en cuenta las consideraciones, como la selección adecuada del valor de K y la optimización de los recursos computacionales. KNIME ofrece diferentes métodos de validación cruzada, como K-Fold Cross Validation, Leave-One-Out Cross Validation y Stratified Cross Validation, para adaptarse a diferentes escenarios de datos.
Cómo se pueden interpretar los resultados obtenidos de la validación cruzada en KNIME para tomar decisiones informadas sobre los modelos predictivos
La validación cruzada en KNIME es una técnica utilizada para evaluar y comparar modelos predictivos. Permite estimar qué tan bien se desempeñará un modelo en datos no vistos. Los resultados de la validación cruzada proporcionan métricas como el error de entrenamiento y el error de prueba promedio, que son útiles para tomar decisiones informadas sobre qué modelo seleccionar.
El error de entrenamiento promedio es una medida del ajuste del modelo a los datos de entrenamiento. Un error bajo indica un buen ajuste, pero también puede indicar sobreajuste si el error de prueba es alto. Por otro lado, el error de prueba promedio es una medida del desempeño del modelo en datos no vistos. Un error bajo indica un buen desempeño y generalización.
Al interpretar los resultados de la validación cruzada en KNIME, es importante tener en cuenta que los valores de error pueden variar según el número de divisiones o pliegues utilizados. Cuanto mayor sea el número de pliegues, más precisa será la estimación del error, pero también más costosa computacionalmente.
Interpretación de las métricas de validación cruzada
En KNIME, las métricas de validación cruzada incluyen el RMSE (Error cuadrático medio), el MAE (Error absoluto medio), el R-squared (coeficiente de determinación) y el RMSLE (Error cuadrático medio logarítmico). Estas métricas proporcionan información sobre la precisión y la calidad de ajuste del modelo.
El RMSE es una medida de la diferencia entre los valores reales y los valores predichos por el modelo. Un RMSE bajo indica un buen ajuste del modelo a los datos. El MAE proporciona una medida similar, pero sin elevar al cuadrado los errores. El R-squared indica qué tan bien el modelo se ajusta a los datos y varía entre 0 y 1, donde 1 indica un ajuste perfecto.
El RMSLE es útil cuando los valores de la variable objetivo están sesgados y tienen una amplia gama. Aplica una transformación logarítmica a los valores antes de calcular el error. Cuanto más bajo sea el RMSLE, mejor será la capacidad del modelo para predecir los valores de la variable objetivo.
Consideraciones adicionales
Además de las métricas de validación cruzada, es importante considerar otros aspectos al tomar decisiones informadas sobre los modelos predictivos. Por ejemplo, la simplicidad del modelo, la interpretación de los coeficientes, la relevancia de las variables predictoras y la robustez del modelo ante cambios en los datos.
La validación cruzada en KNIME es una herramienta poderosa para evaluar modelos predictivos y tomar decisiones informadas. Las métricas de validación cruzada proporcionan información sobre el ajuste y desempeño del modelo, y se pueden interpretar para seleccionar el mejor modelo para un problema específico.
Qué otras estrategias de validación se pueden combinar con la validación cruzada en KNIME para obtener resultados más robustos
Además de la validación cruzada, KNIME ofrece otras estrategias de validación que se pueden combinar para obtener resultados más robustos en el análisis de datos. Una de ellas es la validación aleatoria, que divide el conjunto de datos en diferentes porciones de forma aleatoria y realiza el análisis en cada una de ellas.
Otra estrategia popular es la validación por bloque, que divide los datos en bloques consecutivos y realiza el análisis en cada bloque. Esto es especialmente útil cuando los datos están ordenados en función de un factor relevante para el análisis.
La validación estratificada es otra alternativa, que asegura que las proporciones de las diferentes categorías en los conjuntos de entrenamiento y prueba sean similares. Esto es especialmente útil cuando hay clases desequilibradas en los datos.
Finalmente, la validación temporal es una estrategia que se utiliza cuando los datos tienen una dimensión temporal. Aquí, se divide el conjunto de datos en función del tiempo y se realiza el análisis en diferentes periodos de tiempo.
Preguntas frecuentes (FAQ)
1. ¿Qué es la validación cruzada?
La validación cruzada es una técnica estadística utilizada para evaluar el rendimiento de un modelo en datos no vistos. Se divide el conjunto de datos en k subconjuntos, se entrena el modelo en k-1 subconjuntos y se evalúa en el subconjunto restante.
2. ¿Cómo puedo realizar la validación cruzada en KNIME?
En KNIME, puedes realizar la validación cruzada utilizando el nodo "Cross Validation Loop Start". Este nodo divide el conjunto de datos en k subconjuntos y permite realizar el entrenamiento y la evaluación del modelo en cada uno de ellos.
3. ¿Cuál es el beneficio de la validación cruzada?
La validación cruzada permite obtener una estimación más precisa del rendimiento del modelo en datos no vistos. Al evaluar el modelo en múltiples conjuntos de datos, se reduce la posibilidad de que el rendimiento sea específico de un conjunto de datos en particular.
4. ¿Cuál es el valor adecuado para k en la validación cruzada?
El valor adecuado para k en la validación cruzada depende del tamaño del conjunto de datos y de la cantidad de datos disponibles. Generalmente, se utiliza k=10 en la mayoría de los casos, pero se pueden probar diferentes valores para determinar cuál produce los mejores resultados.
5. ¿Qué métricas se utilizan para evaluar el rendimiento del modelo en la validación cruzada?
Las métricas comunes utilizadas para evaluar el rendimiento del modelo en la validación cruzada incluyen la precisión, el área bajo la curva (AUC), la sensibilidad y la especificidad. Estas métricas proporcionan información sobre la capacidad del modelo para predecir correctamente las clases o categorías.
Envía mensajes en negrita a Slack con KNIME: paso a paso

Maximiza tus datos con SinPecadoPreprocesado en KNIME: Guía completa
KFold en KNIME: Valida datos con eficacia usando esta herramienta
Definir clase objetivo en KNIME: guía paso a paso
Domina los permisos en KNIME y sé un experto en sudo
Aprende cómo usar un nodo para sobredimensionar muestras en KNIME
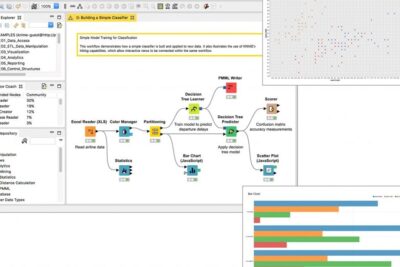
Aprende a hacer validación cruzada con k-fold en KNIME
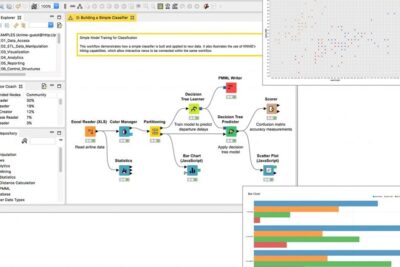
Descarta artículos y preposiciones en KNIME: consejos sencillos

Guía experta para leer y escribir archivos Parquet en KNIME
Deja una respuesta
Lo siento, debes estar conectado para publicar un comentario.
Artículos que podrían interesarte